背景
线上出现大量异常报警、外部接口调用失败,导致线上故障;原因是http连接池配置不合理,写篇文章学习总结;
5.1线上问题
异常堆栈如下
Exception org.apache.http.conn.ConnectionPoolTimeoutException ERROR post error, url:http://xxx, Timeout waiting for connection from pool org.apache.http.conn.ConnectionPoolTimeoutException: Timeout waiting for connection from pool
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:254)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:231)
at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:173)
at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:195)
at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:86)
at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:108)
at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:184)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:82)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:106)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:57)
...
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
问题原因
业务场景:上游rpc调用—>出问题的服务—>下游http服务
1.上游的并发量不高,平时QPS在12左右,报警时在20左右, 2.中间我们的服务QPS大概17左右就上不去了;服务有三台机器; 3.下游服务并未出现压力,接口响应时间稳定在370ms;
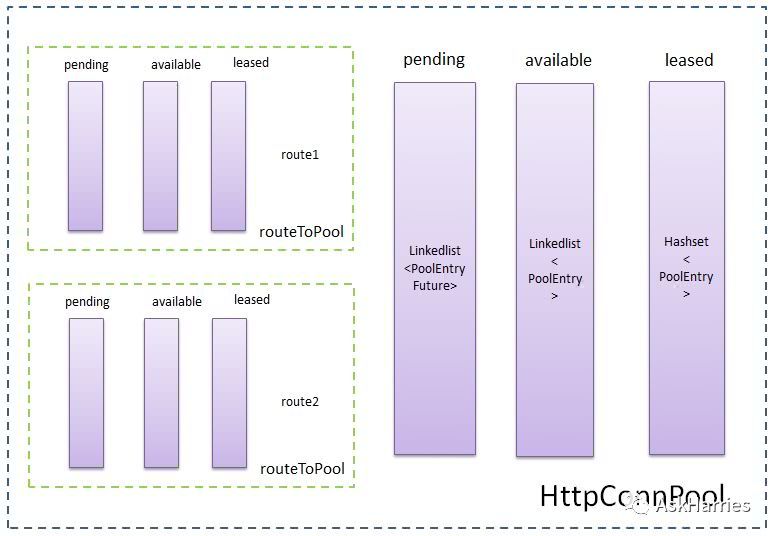
根据我们的服务连接池配置,defaultMaxPerRoute=2 maxTotal=20,每个路由连接数为2,最大连接数20,如下图:
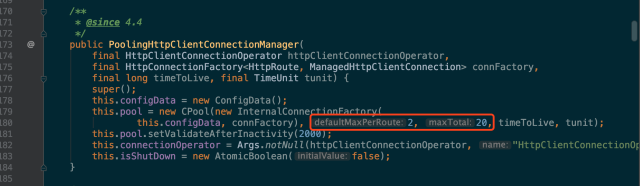
其实写代码的时候根本就没意识到这两个配置,直接用的httpclient的默认配置,基本功问题;
根据连接数的配置我们调用下游接口的QPS容量大概为16.2(1000ms/370ms x 2个连接 x 3台机器),跟我们的监控值基本吻合;
那么问题的很明显了,上游和下游都还没到QPS容量极限,在中间环节因连接配置较小、导致QPS瓶颈,请求打不出去;
解决方法
当时通过手工降级,将下流依赖方改为另外一个、此依赖方接口响应时长在100ms左右,所以在连接数不变的情况下并发可支持到60;
最终解决方案,调大defaultMaxPerRoute、maxTotal;
多了解一些
实际应用中,不同服务之间互相依赖调用很常见(特别是随着微服务理念被各种鼓吹、每个人对微服务的理解又不一样,各种屁大点的服务都被拆成独立应用占用独立的机器资源,这个话题就不在此多说了),那么就会涉及到远程调用,不管用什么调用方式(RPC、HTTP等),往往会存在服务(机器)之间通信、建立连接,也用到连接池,所以多了解一些。
实现网络访问
实现网络调用,无非就是new一个Socket,对Socket进行读写操作,跟普通的new一个Pojo有什么不一样?为何需要一个对象池?
Socket
用Java原生的Socket发送一个HTTP请求,需要以下4步:
- 在服务端口上new Socket;
- 封装HTTP报文、并通过Socket的OutputStream发送到服务端;
- 从Socket的InputStream获取返回结果;
- 解析返回的HTTP报文;
下面是一个HTTP GET请求的测试代码;
@Test
public void testGet() {
try {
String host = HttpTester.TEST_HOST;
int port = HttpTester.TEST_PORT;
String path = HttpTester.TEST_PATH;
SocketAddress address = new InetSocketAddress(host, port);
Socket socket = new Socket();
socket.connect(address);
OutputStreamWriter sw = new OutputStreamWriter(socket.getOutputStream());
BufferedWriter writer = new BufferedWriter(sw);
writer.write("GET " + path + " HTTP/1.1\r\n");
writer.write("Host: " + host + "\r\n");
writer.write("\r\n");
writer.flush();
BufferedInputStream sr = new BufferedInputStream(socket.getInputStream());
BufferedReader reader = new BufferedReader(new InputStreamReader(sr, "utf-8"));
StringBuffer response = new StringBuffer();
String line;
while ((line = reader.readLine()) != null) {
response.append(line);
}
LoggerUtil.logger.info("res : {}", response.toString());
reader.close();
writer.close();
socket.close();
} catch (Exception e) {
LoggerUtil.logger.error("testGet error", e);
}
}
如果用Java自带的HttpURLConnection来写,实现一个POST请求,如下:
@Test
public void testHttpConn() {
try {
InputStream is;
OutputStream os;
BufferedReader reader;
String body = "test.body";
URL url = new URL(TEST_URL);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setDoOutput(true);
conn.setDoInput(true);
conn.setUseCaches(false);
// header
conn.setRequestProperty("Content-Type", "application/json; charset=utf-8");
conn.setRequestProperty("Content-Length", "" + body.getBytes("utf-8").length);
conn.setRequestProperty("Content-Language", "en-US");
conn.setRequestProperty("Connection", "Keep-Alive");
conn.setRequestProperty("Charset", "UTF-8");
// auth
String basicAuth = "Basic " + new String(Base64.getEncoder().encode(body.getBytes()));
conn.setRequestProperty("Authorization", basicAuth);
// time out
conn.setReadTimeout(10 * 1000);
conn.setConnectTimeout(10 * 1000);
os = conn.getOutputStream();
os.write(body.getBytes("utf-8"));
os.flush();
os.close();
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
LoggerUtil.logger.info("content : {}", conn.getContent().toString());
is = conn.getInputStream();
reader = new BufferedReader(new InputStreamReader(is));
StringBuilder content = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
content.append(line);
}
LoggerUtil.logger.info("res : {}", content.toString());
reader.close();
is.close();
} else {
LoggerUtil.logger.info("res code : {}", conn.getResponseCode());
}
conn.disconnect();
} catch (Exception e) {
LoggerUtil.logger.error("testHttpConn error", e);
} finally {
// close
}
}
可以看到,HttpURLConnection帮我们做了HTTP报文的一些封装和解析,比如不用再关心HTTP报文中一些换行符之类的拼接和解析、帮我们简化了开发;
不过有一个问题,频繁创建、关闭连接是有代价的(听说、没有亲自试过),如果业务场景希望对连接进行重用,那么就需要连接池了(当然如果业务场景不需要、那么没必要维护连接池);
HTTP连接
如果用Apache HttpClient来写,代码会简单很多,如下:
@Test
public void postGet() {
HttpGet get = new HttpGet(TEST_URL);
get.addHeader("Content-Type", "application/json; charset=utf-8");
String res = HttpUtils.get(get);
LoggerUtil.logger.info("postGet res : {}", res);
}
public static String get(HttpGet get) {
try {
HttpResponse response = httpClient.execute(get);
return EntityUtils.toString(response.getEntity());
} catch (IOException e) {
LoggerUtil.logger.error("get error, url : {}", get.getURI(), e);
}
return null;
}
TCP
不管用哪种方式实现,通过抓包看其实都是通过TCP进行通信;
到底什么是连接,连接听起来比较抽象,进入HttpClient和HttpURLConnection内部,会发现其实它们都封装了Socket、所以连接指代的就是Socket;
HttpURLConnection做了什么
Java自带的HttpURLConnection在Socket的基础上帮我们封装了HTTP协议;
HttpClient做了什么
Apache HttpClient在Socket的基础上帮我们封装了HTTP协议和连接池的管理;
连接池
连接池主要解决什么问题?
连接复用,避免频繁创建、关闭连接;
设计一个连接池核心点:
- 连接数(最大、最小、核心);
- 等待队列大小;
- 等待时长;
- 空闲时长;
- 拒绝策略;
各种池
池是为了解决什么问题?比如我们常见到的:数据库连接池、线程池等等;
如上我们所说的http连接池一样,池是为了避免频繁创建某些资源(包括但不限于线程、连接等资源),为了达到资源复用;当然如果某些资源创建的代价不大(大小如何衡量呢?)就没必要用池了;
问题
BIO/NIO/AIO区别
Apache HttpClient是BIO吗?有NIO的实现吗?
Netty可以做为HttpClient的替代品吗?
RPC和HTTP区别
相似处:
RPC和HTTP都属于网络应用层,在实现方式上,多数框架都底层都采用了TCP进行可靠通信;
RPC的Service、Method也可以认为是一种路径标识,在某IP:PORT上部署XxxServie、XxxService下有若干method,类似于HTTP的URL路径;
不同处:
协议不同,一般来说RPC框架的协议要比HTTP协议精简;但是也有一些RPC框架使用HTTP协议,比如grpc使用HTTP2协议;
HTTP和TCP的长连接
HTTP keep-alive是为了连接复用,同一个连接上串行方式发送/接收请求;tcp keepalive是为了心跳检测;
HTTP连接池与keep-alive的关系,连接池是对多个连接进行生命周期的管理,keep-alive是对一个连接本身的复用机制;
Ref
whats-the-behavioral-difference-between-http-stay-alive-and-websockets