柒八块表的博客
-
kafka学习

背景
学习Kafka
业务场景
场景一 用户支付成功后,通知商家接单、通知结算记录流水、新老客服务(由新客变为老客)、统一订单中心变更状态;
状态N–>N个调用;
场景二 商家接单成功后,给用户发短信;
场景三 用户取消后,通知商家、通知结算记录退款流水;
设计一个转发服务
一个服务发消息、其它服务监听消息;
设计要点
生产端调用–>转发服务–>存储日志–>广播
receive(String msg)
send(String msg)
怎么做
-
apache httpclient 连接池配置引发的问题
背景
线上出现大量异常报警、外部接口调用失败,导致线上故障;原因是http连接池配置不合理,写篇文章学习总结;
5.1线上问题
异常堆栈如下
Exception org.apache.http.conn.ConnectionPoolTimeoutException ERROR post error, url:http://xxx, Timeout waiting for connection from pool org.apache.http.conn.ConnectionPoolTimeoutException: Timeout waiting for connection from pool at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.leaseConnection(PoolingHttpClientConnectionManager.java:254) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager$1.get(PoolingHttpClientConnectionManager.java:231) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:173) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:195) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:86) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:108) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:184) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:82) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:106) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:57) ... at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)问题原因
业务场景:上游rpc调用—>出问题的服务—>下游http服务
1.上游的并发量不高,平时QPS在12左右,报警时在20左右, 2.中间我们的服务QPS大概17左右就上不去了;服务有三台机器; 3.下游服务并未出现压力,接口响应时间稳定在370ms;
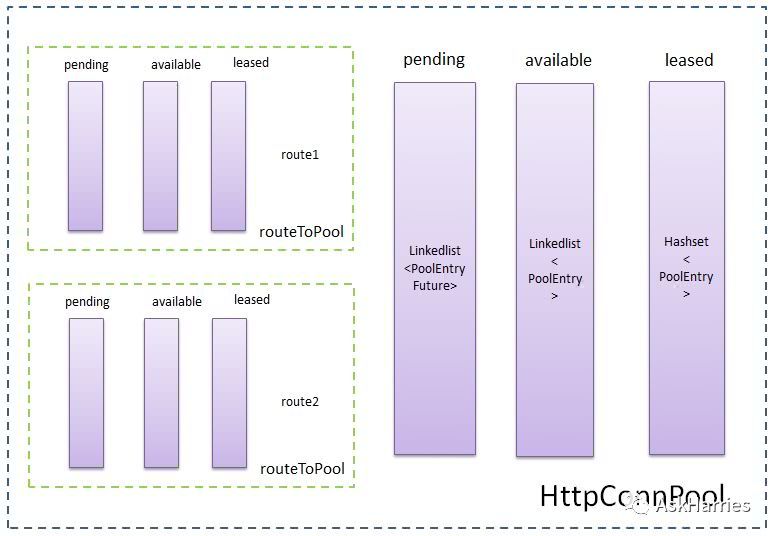
根据我们的服务连接池配置,defaultMaxPerRoute=2 maxTotal=20,每个路由连接数为2,最大连接数20,如下图:
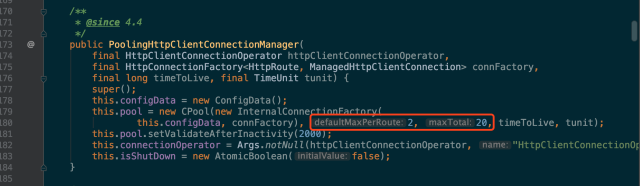
其实写代码的时候根本就没意识到这两个配置,直接用的httpclient的默认配置,基本功问题;
根据连接数的配置我们调用下游接口的QPS容量大概为16.2(1000ms/370ms x 2个连接 x 3台机器),跟我们的监控值基本吻合;
那么问题的很明显了,上游和下游都还没到QPS容量极限,在中间环节因连接配置较小、导致QPS瓶颈,请求打不出去;
解决方法
当时通过手工降级,将下流依赖方改为另外一个、此依赖方接口响应时长在100ms左右,所以在连接数不变的情况下并发可支持到60;
最终解决方案,调大defaultMaxPerRoute、maxTotal;
多了解一些
实际应用中,不同服务之间互相依赖调用很常见(特别是随着微服务理念被各种鼓吹、每个人对微服务的理解又不一样,各种屁大点的服务都被拆成独立应用占用独立的机器资源,这个话题就不在此多说了),那么就会涉及到远程调用,不管用什么调用方式(RPC、HTTP等),往往会存在服务(机器)之间通信、建立连接,也用到连接池,所以多了解一些。
实现网络访问
实现网络调用,无非就是new一个Socket,对Socket进行读写操作,跟普通的new一个Pojo有什么不一样?为何需要一个对象池?
Socket
用Java原生的Socket发送一个HTTP请求,需要以下4步:
- 在服务端口上new Socket;
- 封装HTTP报文、并通过Socket的OutputStream发送到服务端;
- 从Socket的InputStream获取返回结果;
- 解析返回的HTTP报文;
下面是一个HTTP GET请求的测试代码;
@Test public void testGet() { try { String host = HttpTester.TEST_HOST; int port = HttpTester.TEST_PORT; String path = HttpTester.TEST_PATH; SocketAddress address = new InetSocketAddress(host, port); Socket socket = new Socket(); socket.connect(address); OutputStreamWriter sw = new OutputStreamWriter(socket.getOutputStream()); BufferedWriter writer = new BufferedWriter(sw); writer.write("GET " + path + " HTTP/1.1\r\n"); writer.write("Host: " + host + "\r\n"); writer.write("\r\n"); writer.flush(); BufferedInputStream sr = new BufferedInputStream(socket.getInputStream()); BufferedReader reader = new BufferedReader(new InputStreamReader(sr, "utf-8")); StringBuffer response = new StringBuffer(); String line; while ((line = reader.readLine()) != null) { response.append(line); } LoggerUtil.logger.info("res : {}", response.toString()); reader.close(); writer.close(); socket.close(); } catch (Exception e) { LoggerUtil.logger.error("testGet error", e); } }如果用Java自带的HttpURLConnection来写,实现一个POST请求,如下:
@Test public void testHttpConn() { try { InputStream is; OutputStream os; BufferedReader reader; String body = "test.body"; URL url = new URL(TEST_URL); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod("POST"); conn.setDoOutput(true); conn.setDoInput(true); conn.setUseCaches(false); // header conn.setRequestProperty("Content-Type", "application/json; charset=utf-8"); conn.setRequestProperty("Content-Length", "" + body.getBytes("utf-8").length); conn.setRequestProperty("Content-Language", "en-US"); conn.setRequestProperty("Connection", "Keep-Alive"); conn.setRequestProperty("Charset", "UTF-8"); // auth String basicAuth = "Basic " + new String(Base64.getEncoder().encode(body.getBytes())); conn.setRequestProperty("Authorization", basicAuth); // time out conn.setReadTimeout(10 * 1000); conn.setConnectTimeout(10 * 1000); os = conn.getOutputStream(); os.write(body.getBytes("utf-8")); os.flush(); os.close(); if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) { LoggerUtil.logger.info("content : {}", conn.getContent().toString()); is = conn.getInputStream(); reader = new BufferedReader(new InputStreamReader(is)); StringBuilder content = new StringBuilder(); String line; while ((line = reader.readLine()) != null) { content.append(line); } LoggerUtil.logger.info("res : {}", content.toString()); reader.close(); is.close(); } else { LoggerUtil.logger.info("res code : {}", conn.getResponseCode()); } conn.disconnect(); } catch (Exception e) { LoggerUtil.logger.error("testHttpConn error", e); } finally { // close } }可以看到,HttpURLConnection帮我们做了HTTP报文的一些封装和解析,比如不用再关心HTTP报文中一些换行符之类的拼接和解析、帮我们简化了开发;
不过有一个问题,频繁创建、关闭连接是有代价的(听说、没有亲自试过),如果业务场景希望对连接进行重用,那么就需要连接池了(当然如果业务场景不需要、那么没必要维护连接池);
HTTP连接
如果用Apache HttpClient来写,代码会简单很多,如下:
@Test public void postGet() { HttpGet get = new HttpGet(TEST_URL); get.addHeader("Content-Type", "application/json; charset=utf-8"); String res = HttpUtils.get(get); LoggerUtil.logger.info("postGet res : {}", res); } public static String get(HttpGet get) { try { HttpResponse response = httpClient.execute(get); return EntityUtils.toString(response.getEntity()); } catch (IOException e) { LoggerUtil.logger.error("get error, url : {}", get.getURI(), e); } return null; }TCP
不管用哪种方式实现,通过抓包看其实都是通过TCP进行通信;
到底什么是连接,连接听起来比较抽象,进入HttpClient和HttpURLConnection内部,会发现其实它们都封装了Socket、所以连接指代的就是Socket;
HttpURLConnection做了什么
Java自带的HttpURLConnection在Socket的基础上帮我们封装了HTTP协议;
HttpClient做了什么
Apache HttpClient在Socket的基础上帮我们封装了HTTP协议和连接池的管理;
连接池
连接池主要解决什么问题?
连接复用,避免频繁创建、关闭连接;
设计一个连接池核心点:
- 连接数(最大、最小、核心);
- 等待队列大小;
- 等待时长;
- 空闲时长;
- 拒绝策略;
各种池
池是为了解决什么问题?比如我们常见到的:数据库连接池、线程池等等;
如上我们所说的http连接池一样,池是为了避免频繁创建某些资源(包括但不限于线程、连接等资源),为了达到资源复用;当然如果某些资源创建的代价不大(大小如何衡量呢?)就没必要用池了;
问题
BIO/NIO/AIO区别
Apache HttpClient是BIO吗?有NIO的实现吗?
Netty可以做为HttpClient的替代品吗?
RPC和HTTP区别
相似处:
RPC和HTTP都属于网络应用层,在实现方式上,多数框架都底层都采用了TCP进行可靠通信;
RPC的Service、Method也可以认为是一种路径标识,在某IP:PORT上部署XxxServie、XxxService下有若干method,类似于HTTP的URL路径;
不同处:
协议不同,一般来说RPC框架的协议要比HTTP协议精简;但是也有一些RPC框架使用HTTP协议,比如grpc使用HTTP2协议;
HTTP和TCP的长连接
HTTP keep-alive是为了连接复用,同一个连接上串行方式发送/接收请求;tcp keepalive是为了心跳检测;
HTTP连接池与keep-alive的关系,连接池是对多个连接进行生命周期的管理,keep-alive是对一个连接本身的复用机制;
Ref
whats-the-behavioral-difference-between-http-stay-alive-and-websockets
-
code review杂谈

背景
最近几次审pr,发现一些同学出一些低级错误,怎么能避免这些问题,提升代码质量、提高对代码的敬畏之心,重新捡起了code review这件事;
为什么
为什么要code review?
让写代码的人意识到,自己的代码是会被别人看的,对代码有敬畏;
能解决什么
让写代码的人心存一些敬畏;
修正团队代码风格;
不能解决什么
不要指望code review能review出来bugs,bugs只是副加品;
怎么做
不可能做到每次代码改动都在组内开会review,但是每次上线前都需要提pr,由pr人review审核通过;
定期在组内组织reivew,每人都有份;
Ref
http://blakesmith.me/2015/02/09/code-review-essentials-for-software-teams.html
-
业务系统开发的一些场景

背景
在做业务开发时,经常会遇到一些问题及一些通用的模式;
重试
回调
幂等
推VS拉
延时
多系统间数据一致性
业务场景1:先更新数据库、再更新缓存,如果数据库更新成功缓存更新失败,如何保证缓存可以更新成功?
业务场景2:先更新数据库、再调用外部接口并取得外部接口结果,如何保证数据库操作成功、外部接口也调用成功?
思路1:本地事务化,事件发生在哪个系统,将事件记录到本地数据库(本地事务),通过补偿重试或回滚机制保证最终一致;
异步处理业务
发送邮件、发送失败如何处理;
-
Hbase安装启动

背景
学习Hbase的使用,先本地安装下;
只介绍单机模式和伪分布式模式的安装,参考安装教程:Quick Start;
单机模式
安装JDK
安装好JDK,此处不做过多介绍,我选择的JDK1.8,配置好JAVA_HOME环境变量;
下载HBase
选择一个版本下载Apache Download Mirrors,此处我下载的是hbase-2.0.4-bin.tar.gz;
tar xzvf hbase-2.0.4-bin.tar.gz cd hbase-2.0.4确保JAVA_HOME已经设置;
配置文件1
编辑配置文件conf/hbase-site.xml,将hbase.rootdir和hbase.zookeeper.property.dataDir更改为自己的目录;
默认不配置Hbase和ZK的路径,HBase会在/tmp目录下自动创建数据写入的文件夹,一些操作系统会在机器重启时自动清除/tmp目录下的内容,会导致数据丢失;
<configuration> <property> <name>hbase.rootdir</name> <value>file:///home/testuser/hbase</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/testuser/zookeeper</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration>启动Hbase
执行bin/start-hbase.sh脚本启动Hbase,单机模式下HMaster、HRegionServer、ZK都在同一JVM中,执行jps命令可以看到HMaster进程,并且通过HBase Web UI可以看到HBase管理界面;
如下图:
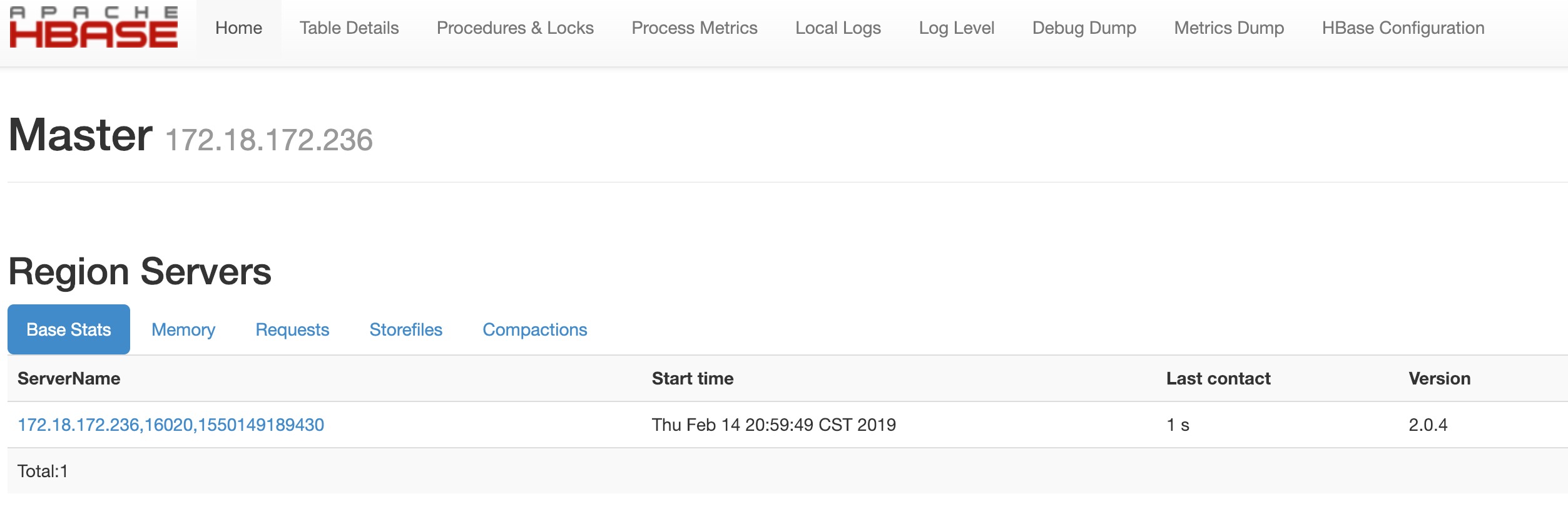
然后可以通过bin/hbase shell在命令行执行Hbase命令,此处不做过多介绍,下面介绍伪分布式模式的安装;
伪分布式模式
zookeeper
下载并启动zookeeper,参见
hadoop
下载并安装hadoop,参见
此处我用的是hadoop伪分布式模式;
启动成功后,可以访问Hadoop Web UI
通过jps命令可以看到nameNode和dataNode线程:
➜ hadoop-2.7.7 jps 70433 Jps 70176 DataNode 70087 NameNode 69274 QuorumPeerMain 70285 SecondaryNameNodehbase
修改配置文件conf/hbase-site.xml:
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> </configuration>执行hbase启动命令:bin/start-hbase.sh,启动成功执行jps命令可以看到HMaster和HRegionServer线程,如下:
➜ hbase-2.0.4 jps 70176 DataNode 70707 Jps 70547 HQuorumPeer 70087 NameNode 70600 HMaster 69274 QuorumPeerMain 70669 HRegionServer 70285 SecondaryNameNode此时也可以通过Hbase Web UI查看;
到hadoop安装目录执行./bin/hadoop fs -ls /hbase 命令,可以看到HDFS中存在/hbase目录,如下:
➜ hadoop-2.7.7 ./bin/hadoop fs -ls /hbase 19/03/21 21:31:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 13 items drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/.hbck drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/.tmp drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/MasterProcWALs drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/WALs drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/archive drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/corrupt drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/data drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/hbase -rw-r--r-- 3 junweizhang supergroup 42 2019-03-21 21:30 /hbase/hbase.id -rw-r--r-- 3 junweizhang supergroup 7 2019-03-21 21:30 /hbase/hbase.version drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/mobdir drwxr-xr-x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/oldWALs drwx--x--x - junweizhang supergroup 0 2019-03-21 21:30 /hbase/staging然后便可以通过hbase shell执行hbase命令了,参见
解决什么问题
大数据实时读写;官网说数据上亿或十亿,其实目前对于MySQL来说单表上亿、单列索引
适用场景
-
小龙说

背景
每次张小龙内部讲话后,都会有一群人转发,我也学习下;
看完这次的演讲,个人感觉张小龙是一个务实的人;
PPT内容
因你看见所以存在
微信启动页多年以为没变化,是这张会让人产生想像力、每个人的想你都不一样,并且同一个人不同时间段的想像也不一样;
从我自己来说,我看到微信启动页的时候只感觉这张图挺好看、挺清爽的,如果拿它来当手机背景也不错,并不会产生想像或问题:这人在干嘛、这个在想什么的这些想法;
关于设计原则
一位德国的产品设计师Rams总结过好的设计的十个原则(这位设计师也曾经是苹果公司特别推崇的一个人):
- 第一个原则是好的产品富有创意,必须是一个创新的东西;
- 第二个是好的产品是有用的;
- 第三个是好的产品是美的;
- 第四个是好的产品是容易使用的;
- 第五个是好的产品是很含蓄不招摇的;
- 第六个原则是好的产品是诚实的;
- 第七个是好的产品经久不衰,不会随着时间而过时;
- 第八个原则是好的产品不会放过任何细节;
- 第九个是它是环保的,不浪费任何资源的;
- 第十个是尽可能少的设计,或者说少即是多;
有人说微信“克制”,克制只是一种表象、在表象之后微信是遵循了一定的设计原则、是这些设计原则约束了产品团队;
如果目标就是获取流量、那么以获取流量为目的并不能说是错的,只是获取手段不一样、获取途径有高低;
如果说微信本身就是个流量载体,微信启动页的流量相当大、但是如果在启动页放广告影响了整体、那么得不尝失,显示是不能放广告的,如果不放广告而放其它的有意思内容、能促进流量那么是不是可以一试?但如果微信的目标不是获取流量,那么在启动页就无需这么做了,一个产品大家喜不喜欢用、不是靠启动页来决定的。
因为遵循原则,很多东西我们又必须坚持去改变;
其实任何一个大的改版都会带来用户的不满,因为人习惯于自己熟悉的界面,觉得是最好的。我们没办法让10亿人来投票决定什么是好的,也投不出来。那怎么才能通过改变寻求设计的优化,让它变得更好呢?这个决策必须遵循好的设计原则。
重要的是我们必须要用我们的产品不停的适应时代,而不是因为害怕用户的抱怨就不去改变它。
尤其是UI上,我们永远不可能让所有的人满意。但是,我们比如让产品越来越美,符合甚至引导当前用户的审美,而不是落伍于时代。
关于微信的历史
我发现很多想法是突如其来的,或者说,是上帝编好程序,在合适的时候放到你的脑袋中的。
我的理解: 成功有时候确实有很大运气的成份,但是在运气之外,你需要武装好自己;
我们后来的很多产品,都有邮箱阶段的影子在里面,比如订阅号、朋友圈。因为在阅读空间里面,我们尝试了各种社交的形式,基于社交的阅读,朋友推荐文章并且可以在下面共同来评论。
我的理解: 公众号、朋友圈其实在邮箱时代就有,只不过是在微信重演罢了,这些本质问题其实早已思考过;
由于阅读空间在邮箱里只是一个分支,所以它能做的用户量并不是特别大。所以做到一定的阶段,也觉得这里差不多走到一个尽头,应该去切换一下方向。
我的理解: 因为局限、所以玩不出太多花样;
当kik出现时,我意识到这里是一个机会,这个机会不是因为kik的产品本身,而是我自己当时开始用智能手机,而很多基于PC的产品或者短信都不能实现很好的沟通体验。所以当时想法很简单,希望给我自己或者少数人做一个沟通的工具。而且我们刚好有一个团队在做QQ邮箱手机客户端,所以刚好凑了十个人的团队开始做微信。包括后台开发,三个手机平台的前端开发,还有UI,加我自己带了一个产品毕业生,就十个人。经过两个月的时间,做出了第一个版本。
我的理解: 对业务保持关注和敏感,自己认可这个产品,十人两个月做出第一版,试问目前的10人团队能做到的有多少?产品初期就是需要糙快猛的上线,先验证想法、再步步迭代,花再多时间搞架构、搞设计、代码再漂亮,完不成第一目标依然无用,唯快不破,时间最宝贵;
一个新的产品没有获得一个自然的增长曲线,我们就不应该去推广它;
我的理解: 暂时不理解,还是说因为微信成功了所以这么说,如果是米聊、获得增长曲线了吗?米聊为什么没做起来?如果大家做产品都这么谦虚,可行吗?
第一我们没有批量导入某一批好友,而是通过用户手动一个一个挑选。第二,在一个产品还没有被验证只能够产生自然增长的时候,我们没有去推广它;
我的理解:米聊是怎么做的?
我其实特别庆幸,能伴随这样一款产品走过了过去的八年,并且,我一直把自己当作产品经理而非职业管理者看待,我认为这是必要的,因为好的产品需要一定的独裁,否则它将包含很多不同意见以至于产品性格走向四分五裂。
我的理解: 产品经理和职业管理者是不同的,要把定位做好;适当的独裁是需要的,但是这个度每个人都会不一样;
初心与原动力
第一,坚持做一个好的,与时俱进的工具
现在这样一个商业环境下,广大用户其实对于糟糕的强迫式体验容忍度是很高的。
人们会以为很多东西是正常的,比如开屏广告是正常的、系统推送的营销信息是正常的,诱导你去点击一些链接是正常的,这样坏的案例特别多。如果回到短信时代,每个人手机里面垃圾信息比正常信息还要多,可怕的不是垃圾信息更多,而是大家会认为这是正常的。
所以微信一直坚持底线,我们要做一个好的工具,可以陪伴人很多年的工具,在用户看来,这个工具就像他的一个老朋友。
它应该紧随时代的潮流,甚至引导时代的潮流。
现在我们看到,微信从很多方面融入到大家的生活中,群聊、朋友圈、红包、公众号、小程序等等。我觉得微信实现了生活方式这个梦想。
第二个原动力是,“让创造者体现价值”
利用互联网,地理不再是优势,你的服务质量才是优势;
关于时长,还有个很有意思的例子,朋友圈从刚发布到现在,用户的每个人的好友可能越来越多,理论上里面的内容也越来越多。但是大家可能想不到的一点是,随着你的好友越来越多,内容越来越多,每个人每天在朋友圈里花的时长却基本是固定的,大概就是30分钟左右。当好友少的时候,你会看得更认真一些,更慢一些。当好友多了以后,你会放得更快一些。
小程序
现在有很多其他公司都在做小程序了。我觉得这是好事情。可能有一些代码的接口跟我们一样,但是我并不担心这里面会跟我们构成很大的威胁。虽然是做同一种东西,除了平台和团队不同,其实更重要的一个差别在于,你的原动力是什么?
我的理解: 学皮毛容易、学内在难;
回顾一下小程序,从最早酝酿到现在三年了,其实看起来挺慢的。我觉得小程序是我们,或者说也是我个人职业生涯里面最大的一个挑战。因为我们从来没有试过还没做一个事情,就先宣布出来了。
我的理解: 小程序的迭代是慢一些,但前提是微信已经很成功了;好多事不是确信成功才去做、而是边做边看、边做边摸索,用邓公的一句话就是:摸着石头过河;
为什么非要做这个事情?因为我认为这就是一个未来必然的趋势。因为APP还要下载安装,网页的体验又太糟糕。这点,在之前的公开课,我已经详细讲过了,就不重复了。
我的理解: TODO,找一找之前的公开课,认真看看
所以我们做过一些试点,比如说我要查一个航班号,是可以输入一个航班号就搜到小程序。但这只是一个试点,我们还没有做到对于所有的小程序都能够通过搜索来找到它的内容,直接把用户连接到小程序去。
我的理解: 通过关键词找工具、找app、找应用,对百度有威胁吗?对app store有威胁吗?
比如很多人说小程序为什么不能发通知或推送?
我的理解: 遵循原则,不要对用户造成骚扰;
小游戏
创新是无限的,发挥创造力;
一切盈利都是做好产品做好服务后的自然而来的副产品。
我的理解: 务实、经世致用
公众号
如果我简单回顾一下公众号的历史的话,在刚发布的时候,确实有很多人利用这样一个当时的流量口获得了巨大的粉丝。在当时,公众号有一个特别好的现象,就是最早的公开课里面分享过一个数据,当时的公众号阅读量其实70%、80%来自朋友圈的转发,只有20%、30%是来自于订阅号的。为什么我觉得它特别好?其实它符合一个二八定律,有20%的人去挑选信息,有80%的人去获益,通过20%的人挑选去阅读文章。
我的理解: 数据说话
社交
可以透露一个数据,从发布到现在,每天进去朋友圈的人数一直在增长,没有停下来的势头。到现在每天有7.5亿人进去朋友圈,平均每个人要看十几次,所以每天的总量是100亿次。
我的理解: 朋友圈本身就是个社交行为
其实视频动态来说,很多人说微信要大力来做视频了,我并不认同,微信怎么可能去做某一种技术领域的事情呢?视频只是一个技术,微信要做的是通讯社交的事情,所以视频对于微信来说只是一个载体,微信要做的是在这一块来说希望做社交。是要做朋友圈之外的另外一种社交的模式,解决上面说的弊端。
我的理解: 着眼点在社交、而不是视频,视频只是社交的一个载体
我们希望这里的视频动态是朋友圈的反面,这里提倡的是真实的,而不是美的。所以大家如果仔细留心一下,你在拍完一个视频动态底下的按钮不叫“完成”、不叫“发表”,不叫发表,而是“就这样”。
我的理解: 是为了实现朋友圈不能实现的需求
阅读
事实上这几年下来,朋友圈的分享的文章阅读率确实在下降。因为当一个人的好友越来越多,他的朋友圈内容越来越多,他反而会跳过那些文章,去关注一下朋友们真实生活里面的照片。他其实并不太愿意从朋友圈里面中断,花几分钟阅读一篇文章,然后再回到朋友圈。用户其实是需要有一个固定的相对长的时间,他才会沉下心来花时间去完成一个阅读动作。这个时候,另外一个阅读氛围更强的入口,对用户来说是更必要的。
我的理解: 了解需求,用数据说话
这样就给我们留下一个机会:我们应该在朋友圈之外,另外开辟一个阅读的一个圈子,一个不是为了看朋友的生活分享,而看文章的地方。这就是看一看。
我的理解: 需求细分
我一直很相信通过社交推荐来获取信息是最符合人性的。因为在现实里面,我们其实接纳新的信息,并不是我们主动到图书馆或者到网上去找的信息。大部分情况都是听到周边的人的推荐而获得的。
我的理解: 社交是用户获取信息的一种途径
信息流
这里我并不想用一些标签来定义这是什么东西。因为标签只是一种表现形式而已。就像我们现在做一个视频动态,我们并不是说我们做了一个视频功能,而是我们做了一种让用户去拍摄和展现自己的一种功能,这个功能是什么样的载体?所以我们并不考虑什么是信息流,而是用一个什么样合理的方式来展现信息。
我的理解: 不要太在意一些title、名词,要看它背后的实质
AI
微信投入了很多精力来做AI。大家以为微信里面的语音识别是第三方来做的,其实它是微信内部语音识别的团队在长达好几年的时间里面一直在做的工作,并且每天在优化它识别的准确率。所以到今天,大家会觉得这里面识别率越来越高了。当我们投入在做语音识别的时候,其实业界对AI这一块还并没有特别大的关注。所以说,我们并不会去跟风来做一个AI,而是说,AI是要落地到我们实际的一个功能或者是场景里面去的。
我的理解: 不跟风、要务实,技术效果再屌炸天也得有实际用处,否则就是浪费钱、浪费时间、浪费生命、浪费社会资源;
所以对于AI来说,其实从技术上来说,我们是特别认同它。但是我们一直认为,好的技术是为产品服务的,AI应该默默躲在后面帮助用户来做一些事情,就像语音识别一样。
我的理解: 技术是为业务服务的,那么有些人说的技术驱动还可信吗?现实当中有了痛点、想办法去解决,驱动技术前进、技术的前进又给人以想像空间,看怎么理解技术驱动这个词了,千万别被一些人口中所有的技术驱动所误导,以为技术就是万能之类的,这些话是需要放在一定背景下才成立;
当我在内部提这些的时候,有同事问我,我们的目标难道不是尽可能的获取用户的点击吗?我们为什么要想那么多产品之外的东西?就像谷歌的员工为什么要反对公司把这一项技术应用在军方项目一样,我认为我们做的每一件事情背后,都是有意义所在的。
我的理解:点击只是目的,要思考背后的原因;
善良
这里就提到关于上次在内部年会里面说的一句话。就是关于善良的,其实我特别害怕一句话被断章取义变成一个句子去传播,这个对于我来说是不太理性的。
我的理解:生活中不要被一些随口听来的话所支配,要想明白了这些话背后的原因,否则便可能是彼之蜜糖我之砒霜;
支付
因为只有用户意识不到的是很好的服务,你都不会想到有这个东西的存在,你付款的时候自然把微信掏出去扫一下二维码,润物细无声的才是一个最好的用户产品体验。
我的理解:好的体验应该是用户不知道你的存在、用的时候惯性一样的拿起便用;
建议大家去试一下,反正我给我的父母开了亲属卡,体验特别好.不仅仅是他们的体验,我的体验也特别好,当你看到他们每一笔消费的时候,你都会觉得你在尽一份孝心,所以告诉大家有这样一个东西。但我们有很多好东西藏得实在太深了,所以有很多的用户根本就不知道有这样的一些东西存在。这是一些小的东西。
我的理解:第一次知道亲属卡,立马开通两张,不过为啥目前只有父母、孩子的分类,总共可发4张,没有配偶、兄弟姐妹等分类?难道设计这个功能的时候是有什么考虑吗?
但是我们在微信里面有一些特别大的东西,就是一直我们做得不够好的,就是我们卡包的能力。我们卡包做了好几年了,一直认为卡和券是很大的品类,是日常要用到一个东西。我们一直想改变一个现状,就是你出门的时候钱包里面还要放那么多卡,当然现在银行卡不需要怎么带的。但是一些线下的店的卡还是要带着,我们的卡包想承载这一块,但是老实说一直还没有做好,所以最近大家在这一块会跃跃欲试,想做新的改变。改变的结果是希望通过消费的行为和电子智能做一种自动的关联,变成人与线下消费连接的通道,实现更好的连接。
我的理解:小龙也有想做但是没做起来的,即使是拥有了微信这么一个流量产品,所以很多事都是有初衷、去实践,成不成只有实践过后才知道,要允许试错;
企业微信
关于企业微信,企业微信如果定位为公司内部的一个沟通工具的话,我认为它的场景和意义会小很多,只有当它延伸到企业外部的时候它会产生更大的价值。企业微信后续新的变化是基于一个新的理念——希望让每一个企业员工都成为企业服务的窗口。人就是服务,而且是认证的服务。
我的理解:创新、IDEA很重要,决定了一个产品的格局,如何去实现这个创意、IDEA,也很重要,二者缺一不可,是X的关系、不是+的关系;
人口红利
微信的目标从来都不是说我们的目标是要扩大用户数,如果要扩大用户数,我们过去几年早去推广,早一点把10亿人都覆盖到就好了。但并不是这样的,我们用户数的增长是自然而然增长的过程,对我们而言,我们要考虑的是对我们已有的用户提供什么服务,这个更重要的问题。
我的理解:务实最重要,解决问题最重要;
因为人口总是有限的,服务才是层出不穷的。在过去可能10年算一个时代,但我觉得自从互联网或者是移动互联网出来的时候,我有一个感觉,三五年就是一个时代了,也就是说时代的更迭更快了,催生出来的需求也是更快了。在这个时代下,创新才是应对未来的唯一办法。
我的理解:创新无止境;
不管怎么样面对这样的需求以微信做事风格的话,如果我们始终像过去的微信一样,我们始终瞄准的是做最好的工具,并且让创造价值的人体现价值这样一个原动力做,我觉得我们再怎么走也不会走得太偏。所以有的时候我们经常有时候会回顾一下,如果我们自己看一下微信这些年改变了什么?其实我们自己也是挺有成就感的。更多的时候,很多人问我们,你们跟别人有什么不一样?我觉得有一个不一样是这样的,我们在思考问题或者是思考做什么的时候我们经常会问自己一个问题,就是我们在做这个事情的意义是什么?
我的理解:时代在变、有一些是不变的,思考很重要、所以有时候孤独并不是一件坏事;
我当然知道很多团队做这个事情他是不问这个意义的,他只问我们的KPI是什么?但是说老实话微信团队从开始成立到现在从来没有瞄准KPI去奋斗过,但是并不妨碍团队能够越做越好。因为就像小程序,如果围绕KPI去做,我们不知道怎么制定KPI,因为它没有这个东西,没有办法制订它的KPI如果围绕一个KPI,大家可能不会做这个事情。
我的理解:对于一些经典的管理手段,并不是适用所有场景,以实际问题为出发点;
我今天讲了特别多,我其实想作为一个总结,因为在之前每次都是讲某一个业务,今天我其实更多的作为一个产品经理跟大家做一个交流,作为一个产品经理,我自己其实能够带领一个团队做出一个10亿级的产品,我当然觉得很有成就感觉对于我来说更加幸运的是可以在这个过程里面把我自己对于世界的认知体现在产品里面,并且成为一个产品的价值观。我觉得这是一个更加难得的一个事情。当然内部有很多同事说我是很独裁,我就认了我就很独裁的,有很多产品是很民主的,但是有很多领导给他施加意见,最后这个产品是没有灵魂的,最后这个产品会支离破碎。一个产品要有很强的认知,这样才能造出一个东西它的内在是一致的。所以在这里要特别感谢一下我们团队,因为平常在工作里面以批评为主,所以今天要借这个公开场合来感谢一下我们这个团队。
我的理解:有种职位叫纯管理、有种职位叫负责人,管理也是一种职业一种岗位,没有对错合适之分,只看目的是啥,如果目的是想做一款好的产品,那么不管团队是多少人,要做一线产品(方式可以有多种多样、不一定自己写需求,但是需求逻辑要按自己的想法来),不能当纯管理,当然团队大的话会花费一些团队管理的时间。要打击那种“小富即安”、沉浸舒适区、划水的思想。
-
2019书单

01
02
03
04
05
06
《封建脉络百战-秦并天下》
07
08
《封建脉络百战-楚汉争霸》
09
10
《封建脉络百战-西汉篇》
11
12
《封建脉络百战-东汉篇》
-
这个事情该谁做
-
jdk1.8-jetty-swap被占满问题排查
背景
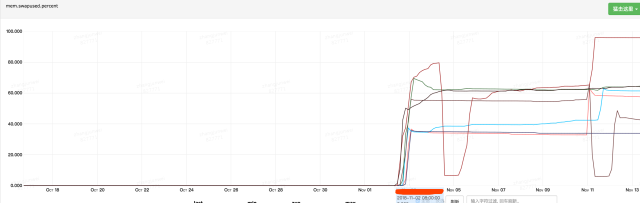
线上服务收到报警,报警内容:虚拟机swap区占用比例超过80%,如图:

本文着重描述排查问题的过程,在这个过程中不断的猜测–>验证–>推翻–>再猜测–>再验证–>再推翻,这个过程更有意思;
swap是什么
潜意识中,当进程需要申请内存而机器内存不够时,需要将一部分不常用的进程、数据换出到swap,从而腾出一部分物理内存空间;
看下关于Linux swap space的介绍:
Linux divides its physical RAM (random access memory) into chucks of memory called pages. Swapping is the process whereby a page of memory is copied to the preconfigured space on the hard disk, called swap space, to free up that page of memory. The combined sizes of the physical memory and the swap space is the amount of virtual memory available.
Swapping is necessary for two important reasons. First, when the system requires more memory than is physically available, the kernel swaps out less used pages and gives memory to the current application (process) that needs the memory immediately. Second, a significant number of the pages used by an application during its startup phase may only be used for initialization and then never used again. The system can swap out those pages and free the memory for other applications or even for the disk cache.
找出哪些进程占用了swap
如果说swap被占用了,说明物理内存不够,那么需要先找出哪些进程占用了swap,再去看看这些进程是什么原因导致占用swap;
线上虚拟机配置内存为8G,swap为2G,可以通过/proc/$(pid)/smaps找到哪些进程占用了swap;
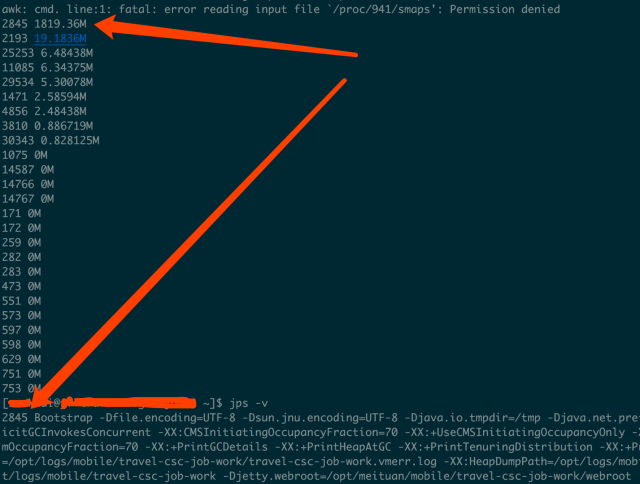
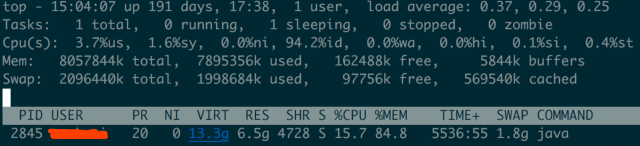
通过top命令我们也可以看到是java进程占用了1.8G的swap区:
什么原因导致java进程需要申请swap
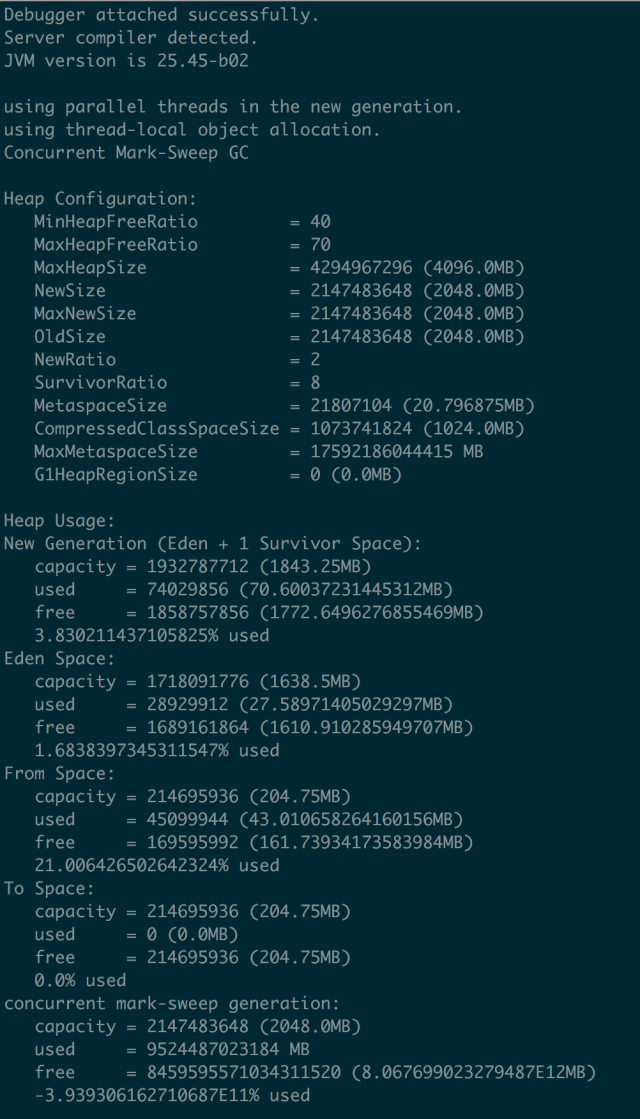
线上jdk1.8,应用启动参数配置:-Xmx4g -Xms4g -Xmn2g,metaspace用的默认;
通过线上发布记录看到,在11-01号下午发布,11-02号swap开始被占用:
所以第一个怀疑的点便是上线发布导致,此次发布包含两块内容:升级jdk1.7至jdk1.8、分单逻辑优化;首先怀疑的是逻辑优化、导致每分钟java堆内存导致大量对象被创建,但是这些对象的生命周期很短、应该会被快速回收,如果是大量对象创建导致占用内存过多,那么gc次数应该比发布前要频繁,所以再来看gc监控:
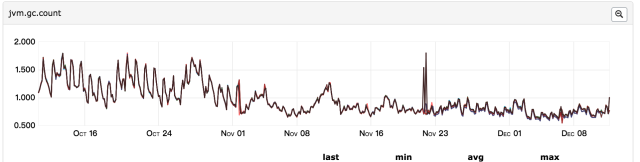
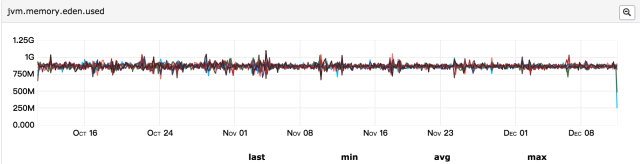
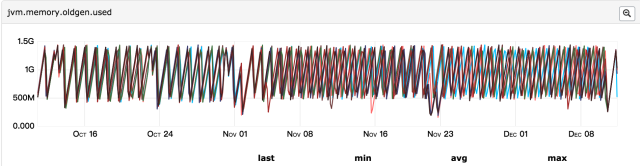
发现gc次数频率与之前相比并无明显变化,并且年轻代和年老代内存都在合理范围内;
所以真的是因为分单逻辑优化导致的吗?
Java堆分配了4G、通过jstat看到metaspace用了200M、线程栈大概占用300M(300左右个线程、每个线程1M内存),总共是4.5G左右,而top命令显示java占用的物理内存为6.5G(RES列显示的数据),另外2G是哪里占用了?堆外内存?
所以我们的思路转向到了堆外内存,看看从这个思路上是否可以找出一些线索;
这里通过google-perftools这个工具来查看java进程内存分配情况,其实接下来的排查思路类似这篇文章:JAVA使用堆外内存导致swap飙高
首先安装google-perftools,见这里,java应用启动时加上google-perftools的配置:
export LD_PRELOAD=/home/user/gperftools/lib/libtcmalloc.so export HEAPPROFILE=/home/user/heap-gperftools/gzip # 此配置表示进程每分配X字节内存输出一个文件,默认是1G输出一个文件 export HEAP_PROFILE_ALLOCATION_INTERVAL=4073741824 # 此配置表示进程每使用X字节内存输出一个文件,默认是100M输出一个文件,对于我这个应用来说,刚启动生成50多个文件,不便于分析问题,所以我设置的4G左右 export HEAP_PROFILE_INUSE_INTERVAL=4048576000环境变量配置好重启java应用,此时在目录下就可以看到生成的gzip.0001.heap类的文件,来分析这些文件:
/home/sankuai/gperftools/bin/pprof –text /usr/local/java8/bin/java gzip.0001.heap
对输出的结果进行排序显示前20行:
2060.7 79.1% 79.1% 2060.7 79.1% updatewindow 0.0 0.0% 100.0% 2060.7 79.1% Java_java_util_zip_Inflater_inflateBytes 0.0 0.0% 100.0% 2060.7 79.1% inflate 0.0 0.0% 100.0% 2057.3 79.0% 0x00007f764b47ee05 0.0 0.0% 100.0% 2045.5 78.6% 0x00007f764b6c861f 5.5 0.2% 99.9% 455.3 17.5% Java_java_util_zip_Inflater_init 0.0 0.0% 100.0% 452.7 17.4% 0x00007f764b4f8eb0 449.8 17.3% 96.4% 449.8 17.3% inflateInit2_ 0.0 0.0% 100.0% 427.8 16.4% 0x00007f764bb4d16b 45.8 1.8% 98.2% 45.8 1.8% init 0.0 0.0% 100.0% 45.8 1.8% _init@4210 0.0 0.0% 100.0% 45.8 1.8% __do_global_ctors_aux@12b20 0.0 0.0% 100.0% 44.8 1.7% JavaCalls::call_helper 0.0 0.0% 100.0% 43.9 1.7% start_thread 0.0 0.0% 100.0% 42.8 1.6% 0x00007f764b32e4e6 0.0 0.0% 100.0% 41.9 1.6% JavaMain 8.3 1.5% 99.6% 38.3 1.5% os::malloc 0.0 0.0% 100.0% 35.5 1.4% 0x00007f764b33598c 0.0 0.0% 100.0% 28.3 1.1% 0x00007f764b33570f 0.0 0.0% 100.0% 26.3 1.0% jni_invoke_static可以看出Java_java_util_zip_Inflater_inflateBytes方法分配了比较多的内存,再分析其它heap文件,也都是这个方法,所以从这个方法入手继续追踪,需要找到是业务哪行代码调用了Inflater类,这里我们使用btrace这个工具,btace脚本如下;
import static com.sun.btrace.BTraceUtils.*; import com.sun.btrace.annotations.*; import java.nio.ByteBuffer; import java.lang.Thread; @BTrace public class BtracerInflater{ @OnMethod( clazz="java.util.zip.Inflater", //method="inflateBytes" method="inflate" ) public static void traceCacheBlock(){ println("Who call java.util.zip.Inflater's methods :"); jstack(); } }通过打印inflate方法的调用堆栈,找到两处调用:一处是公司的监控组件、一处是jetty启动时扫描jar包会用;
先分析公司的监控组件,监控组件会每隔1分钟去服务器拉取监控配置信息(比如路由IP地址、客户端连接超时时间、长SQL阈值配置等),而服务器返回的配置信息是xml格式,在解析xml时会用到inflate方法,于是我们通过禁用监控组件、重启应用、发现java应用所占的物理内容并没有减少,所以排除是监控组件的问题;
再来看btrace打印的jetty调用栈:
Who call java.util.zip.Inflater's methods : java.util.zip.Inflater.inflate(Inflater.java) java.util.zip.InflaterInputStream.read(InflaterInputStream.java:152) java.io.FilterInputStream.read(FilterInputStream.java:133) java.io.FilterInputStream.read(FilterInputStream.java:133) org.objectweb.asm.ClassReader.a(Unknown Source) org.objectweb.asm.ClassReader.<init>(Unknown Source) org.eclipse.jetty.annotations.AnnotationParser.scanClass(AnnotationParser.java:888) org.eclipse.jetty.annotations.AnnotationParser$2.processEntry(AnnotationParser.java:847) org.eclipse.jetty.webapp.JarScanner.matched(JarScanner.java:161) org.eclipse.jetty.util.PatternMatcher.matchPatterns(PatternMatcher.java:100) org.eclipse.jetty.util.PatternMatcher.match(PatternMatcher.java:82) org.eclipse.jetty.webapp.JarScanner.scan(JarScanner.java:84) org.eclipse.jetty.annotations.AnnotationParser.parse(AnnotationParser.java:859) org.eclipse.jetty.annotations.AnnotationParser.parse(AnnotationParser.java:874) com.xxx.boot.RJRAnnotationConfiguration.parseWebInfClasses(RJRAnnotationConfiguration.java:96) org.eclipse.jetty.annotations.AnnotationConfiguration.configure(AnnotationConfiguration.java:113) org.eclipse.jetty.webapp.WebAppContext.configure(WebAppContext.java:468) org.eclipse.jetty.webapp.WebAppContext.startContext(WebAppContext.java:1247) org.eclipse.jetty.server.handler.ContextHandler.doStart(ContextHandler.java:710) org.eclipse.jetty.webapp.WebAppContext.doStart(WebAppContext.java:494) org.eclipse.jetty.util.component.AbstractLifeCycle.start(AbstractLifeCycle.java:64) org.eclipse.jetty.server.handler.HandlerCollection.doStart(HandlerCollection.java:229) org.eclipse.jetty.util.component.AbstractLifeCycle.start(AbstractLifeCycle.java:64) org.eclipse.jetty.server.handler.HandlerWrapper.doStart(HandlerWrapper.java:95) org.eclipse.jetty.server.Server.doStart(Server.java:280) org.eclipse.jetty.util.component.AbstractLifeCycle.start(AbstractLifeCycle.java:64) sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) java.lang.reflect.Method.invoke(Method.java:497) com.xxx.Bootstrap.main(Bootstrap.java:101)jetty的调用场景是:为了支持Servlet规范中的注解方式(使得不再需要在web.xml文件中进行Servlet的部署描述,简化开发流程),jetty在启动时会扫描class、lib包,将使用注解方式声明的Servlet、Listener注册到jetty容器,在扫描jar包的时候调用了inflate,分配了大量的内存,此时通过关键词搜索到Memory leak while scanning annotations,这篇文章给出了两种解决方法,一种是评论处所说,禁用缓存(说是jdk1.8的bug):
Here’s a link to the java bugs database issue: http://bugs.java.com/bugdatabase/view_bug.do?bug_id=8156014
I’d like to be able to comment on it, but I can’t seem to find a link to allow me to do that.
The comments I’d like to add are:
the problem is still reproduceable as of jdk8u112
the problem seems to be fixed in jdk9: I tested jdk9ea+149 and couldn’t reproduce
I’ve tried some workarounds for jdk8: it seems the ServiceLoader impl uses the jarurlconnection caching, so it may be of some benefit to try to disable url caching (although not sure of the effects on performance).
Try creating an xml file (eg called “caches.xml”) with the following contents:
<Configure id="Server" class="org.eclipse.jetty.server.Server"> <Set class="org.eclipse.jetty.util.resource.Resource" name="defaultUseCaches">false</Set> <New class="java.io.File"> <Arg> <SystemProperty name="java.io.tmpdir"/> </Arg> <Call name="toURI"> <Call id="url" name="toURL"> <Call name="openConnection"> <Set name="defaultUseCaches">false</Set> </Call> </Call> </Call> </New> </Configure>尝试之后,java进程占用的物理内存由6.5G降到了5.9G,有一定的效果,但是我们估算的java进程应该占4.5G左右,还有1.4G内存被谁占用了呢?
再尝试另外一种方法:
We were investigating a Jetty application that used much more memory than it was supposed to do (near a Gb more than the max heap size plus the max metaspace size). We found out that the extra memory was Native memory, being allocated using malloc via some library (we don’t have native code in our app). Then we used jemalloc ( http://www.canonware.com/jemalloc/) to find out which class was doing this allocation and we found out that it was java.util.zip.Inflater. Via jstack we were able to find calls to the library and the main caller was Jetty, while in the process of looking for annotations. We disable annotations for the application and the memory usage went back to normal.
既然jetty调用是因为扫描jar包中的注解,我们应用中没有通过注解声明的Servlet、Listener,是不是可以不需要扫描这一步,故而在jetty.xml中将注解扫描的方式去掉:
<!-- <Item>org.eclipse.jetty.annotations.AnnotationConfiguration</Item> --> <!-- Item>com.xxx.boot.RJRAnnotationConfiguration</Item> -->再重启应用,发现内存使用由6.5G降到了3.9G,并且应用运行稳定后不再占用swap,如图:
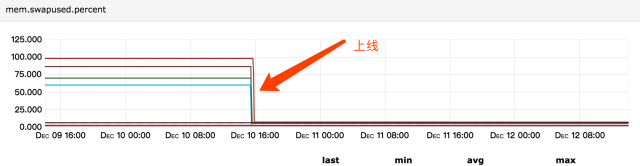
看下对比:
机器 改动 内存使用 系统稳定运行后 机器1 什么都不变 java占用物理内存6.5G 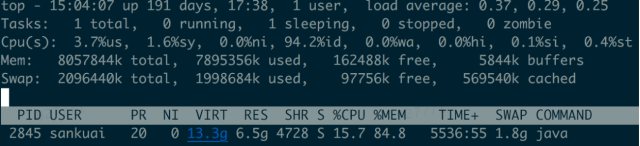
机器2 禁用jetty resource缓存 从6.5G降到5.9G 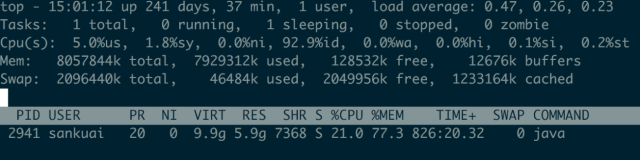
机器3 禁用注解扫描 从6.5G降到3.9G 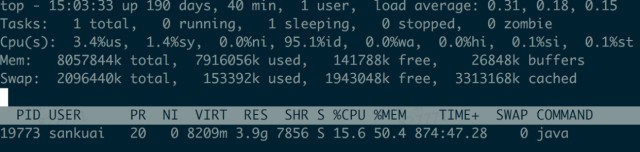
总结
总结下排查问题的大概思路:
- 确认哪些进程占用了swap;(定位到是java进程)
- 理论上java进程不应用占用6.5G物理内存,通过gperftools工具查看java进程内存分配;(排除堆内内存问题,找到java.util.zip.Inflater类分配内存较多)
- 通过btrace定位哪些地方调用了java.util.zip.Inflater类;(排除监控组件的问题、锁定jetty启动调用)
- 尝试不同解决方法;
- 最后物理内存是降了,但是这就是最优解吗?这种方法是不是一种逃避解决方案(相当于不能使用Servlet注解方式)?
- 有没有更好的解决方法?
- 如果说是jdk1.8的问题,那么其它地方用jarurlconnection cache的地方是不是都存在内存泄漏?1.7的实现和1.9的实现是什么样的?
- 其它Servlet容器会不会存在这种问题?Tomcat也实现了Servlet规范,是如何实现的?
发散
虽然最后貌似找到了一种解决方法,但是还有很多疑问,当我们做其它事情的时候,是不是也是像排查这问题这样,不断怀疑–>验证–>思考–>尝试,直至找到一个相对满意的结果,但不一定最优的结果。
像马云马老师在创业未成功时,是不是也是不断的摸索,取得一定结果了、才知道走的路是相对正确的?
那么到底是因为得到了结果才相信、还是因为相信才有的结果?
-
Todo List

Tech
互联网
Reading
Life
读书笔记
《道氏理论》
《振荡指标MACD》
《治史三书》
《西行漫记》
《写给大家看的PPT设计书》
《宿命三国》
《见识》
