柒八块表的博客
-
一代人有人一代的命

背景
看了《无问西东》电影,4个不同年代的人,最后都听从了自己内心的选择,然后我看到的是,在时代洪流中,我们每一个人都是沧海一粟,而这一粟正是形成了时代洪流,所以:
一代人有一代人的命; 一代人有一代人的使命;二十年
二十年一代人;
20后
一寸山河一寸血,十万青年十万军;
40后
黎明前的黑暗,大家起点都一样;
60后
阶级分化;
80后
阶级固化;
00后
家境要比个人努力更占优势;
-
资治通鉴读书笔记

为什么读这本书
想看看编年体历史;
希望18年能将全书通读一遍;
版本
kindle免费版,分20本,文言文基本可看懂;
读书笔记
《周纪》五卷
李牧:李牧不战则已,一战保边境十年平安(单于奔走,十馀岁不敢近赵边。),深得孙子真传;故善战者、无智名、无勇功;正如太祖所说:战争的一个基本原则就是尽可能的保存自己的力量,消灭敌人的力量;看来古今牛人对战争的本质有着一致的看法;从这点来看,诸葛亮六出祁山是不是明知不可而为之?肯定不是因为情怀、因为冲动,偏安一隅取守则亡?
《秦纪》三卷
李斯:忠于名利而非忠于秦,故而身死名灭;
扶苏:因一诏而自杀,且蒙恬已经提醒劝诫,依旧固执可见扶苏也并非明主,若以北境三十万守众清君侧、鹿死谁手尚未知,天亡秦;
《汉纪》六十卷
项羽:典型的战术勤奋战略懒惰;
张良:善始善终,古来几人,不愧为帝王师;对比另外两杰,为臣之道;对比李斯,认清形势;
汉文帝:当皇帝能像文帝一样,百姓就不会造反,帝王者,作到知人善任便可;作为顶层管理者:最重要的学会如何分大饼,百姓少天下亡;
贾谊:古之奇才、天常妒之;博忆宏论;
-
MySQL Replace 自增问题

背景
今天线上环境发现一个用replace into 语句递增问题,我的理解是时间越早自增的id越我,但是这一例却是时间越早、自增的id反而大;
问题描述
业务上需要一个自增序号,于是就用MySQL InnoDB 表实现了一个;表结构如下:
CREATE TABLE `seq` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `ref_id` bigint(20) NOT NULL COMMENT '引用id', `create_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6), PRIMARY KEY (`id`), UNIQUE KEY `index_ref_id` (`ref_id`) ) ENGINE=InnoDB AUTO_INCREMENT=5000 DEFAULT CHARSET=utf8mb4 COMMENT='唯一序号表';然后程序中通过语句实现(业务上会存在同一refId重复提交,所以用的replace而不是insert):
replace into seq (ref_id) values (#{refId);理论上时间越早、seq表的id就越小,但是今天发现两条记录刚好相反:(线上数据库的事务隔离级别为 REPEATABLE-READ,innodb_autoinc_lock_mode为1)
mysql> select * from seq where id in (5237, 5238); +------+--------+----------------------------+ | id | ref_id | create_time | +------+--------+----------------------------+ | 5237 | 1433 | 2018-01-04 11:00:02.736458 | | 5238 | 1396 | 2018-01-04 11:00:02.736385 | +------+--------+----------------------------+下面是两条数据插入时的Binlog日志:
SET TIMESTAMP=1515034802.736385/*!*/; BEGIN /*!*/; # at 959416466 #180104 11:00:02 server id 32145168 end_log_pos 959416533 CRC32 0xd98fea49 Rows_query # replace into seq (ref_id) # values (1396) # at 959416533 #180104 11:00:02 server id 32145168 end_log_pos 959416589 CRC32 0x3f19e645 Table_map: `top_ad_plan`.`seq` mapped to number 474 # at 959416589 #180104 11:00:02 server id 32145168 end_log_pos 959416648 CRC32 0xb50d056a Write_rows: table id 474 flags: STMT_END_F BINLOG ' sphNWh0Qf+oBQwAAANWILzmAACtyZXBsYWNlIGludG8gc2VxIChyZWZfaWQpCiAgICB2YWx1ZXMg KDEzOTYpSeqP2Q== sphNWhMQf+oBOAAAAA2JLzkAANoBAAAAAAEAC3RvcF9hZF9wbGFuAANzZXEAAwgIEQEGAEXmGT8= sphNWh4Qf+oBOwAAAEiJLzkAANoBAAAAAAEAAgAD//h2FAAAAAAAAHQFAAAAAAAAWk2Ysgs8gWoF DbU= '/*!*/; ### INSERT INTO `top_ad_plan`.`seq` ### SET ### @1=5238 /* LONGINT meta=0 nullable=0 is_null=0 */ ### @2=1396 /* LONGINT meta=0 nullable=0 is_null=0 */ ### @3=1515034802.736385 /* TIMESTAMP(6) meta=6 nullable=0 is_null=0 */ # at 959416648 #180104 11:00:02 server id 32145168 end_log_pos 959416679 CRC32 0x98567a1c Xid = 414613759 COMMIT/*!*/; # at 959416679 #180104 11:00:02 server id 32145168 end_log_pos 959416744 CRC32 0xc57084a5 GTID [commit=no] SET @@SESSION.GTID_NEXT= 'f3aa695d-1a7e-11e7-84f7-00228ce195da:19314136'/*!*/; # at 959416744 #180104 11:00:02 server id 32145168 end_log_pos 959416827 CRC32 0x67fab679 Query thread_id=3064136 exec_time=0 error_code=0 SET TIMESTAMP=1515034802.736458/*!*/; BEGIN /*!*/; # at 959416827 #180104 11:00:02 server id 32145168 end_log_pos 959416894 CRC32 0x120a343f Rows_query # replace into seq (ref_id) # values (1433) # at 959416894 #180104 11:00:02 server id 32145168 end_log_pos 959416950 CRC32 0x22b0e030 Table_map: `top_ad_plan`.`seq` mapped to number 474 # at 959416950 #180104 11:00:02 server id 32145168 end_log_pos 959417009 CRC32 0x798a319a Write_rows: table id 474 flags: STMT_END_F BINLOG ' sphNWh0Qf+oBQwAAAD6KLzmAACtyZXBsYWNlIGludG8gc2VxIChyZWZfaWQpCiAgICB2YWx1ZXMg KDE0MzMpPzQKEg== sphNWhMQf+oBOAAAAHaKLzkAANoBAAAAAAEAC3RvcF9hZF9wbGFuAANzZXEAAwgIEQEGADDgsCI= sphNWh4Qf+oBOwAAALGKLzkAANoBAAAAAAEAAgAD//h1FAAAAAAAAJkFAAAAAAAAWk2Ysgs8ypox ink= '/*!*/; ### INSERT INTO `top_ad_plan`.`seq` ### SET ### @1=5237 /* LONGINT meta=0 nullable=0 is_null=0 */ ### @2=1433 /* LONGINT meta=0 nullable=0 is_null=0 */ ### @3=1515034802.736458 /* TIMESTAMP(6) meta=6 nullable=0 is_null=0 */ # at 959417009 #180104 11:00:02 server id 32145168 end_log_pos 959417040 CRC32 0xe8c81a16 Xid = 414613760 COMMIT/*!*/; # at 959417040 #180104 11:00:02 server id 32145168 end_log_pos 959417105 CRC32 0x5b22e732 GTID [commit=no] SET @@SESSION.GTID_NEXT= 'f3aa695d-1a7e-11e7-84f7-00228ce195da:19314137'/*!*/; # at 959417105 #180104 11:00:02 server id 32145168 end_log_pos 959417187 CRC32 0xbd88c985 Query thread_id=2955584 exec_time=0 error_code=0原因
待查找;
结论
如果业务上需要实现自增,不要依赖数据库自增id去实现,因为不可靠,不一定时间越早的id就越小;
You should never depend on the numeric features of autogenerated keys.
-
股票基本指标

指标
个股行情数据
最高:当天股价最高点; 最低:当天股价最低点; 今开:当天开盘价; 昨收:昨天收盘价; 涨停:当天涨停的话,价格能涨到多少; 跌停:当天跌停的话,价格能跌到多少; 成交量:当天成交的手数; 成交额:当天成交的金额; 量比:计算的是相对成交量的指标;量比=(现成交总手数 / 现累计开市时间(分) )/ 过去5日平均每分钟成交量 委比:衡量买卖盘相对强度;委比=(委买手数-委卖手数)/(委买手数+委卖手数)×100% 换手:
-
2018书单
01
《资治通鉴》 年度计划,没看完
02
03
04
《Teach Yourself Scheme in Fixnum Days》
05
06
《分布式系统原理介绍》PDF版
07
《新生》
09
10
12
-
MySQL JDBC 更新数据丢失毫秒精度

背景
业务上需要将MySQL表中的时间精度由原来的“年月日 时分秒”精确到毫秒,但是发现通过MySQL客户端update语句可以更新毫秒成功,但是通过程序却不行,毫秒数始终为0;
原因
经过以上背景描述,第一反应是用程序更新数据库有问题,将精度给搞丢了;我们数据库组件这块用的:Mybatis+C3p0+MySQL Connector,首先将更新语句日志打出来:
2017-12-22 17:27:21,719-[TS] DEBUG main updateByPrimaryKeySelective - ==> Preparing: update schedule SET version = version + 1, apply_time = ? where id = ? 2017-12-22 17:27:21,732-[TS] DEBUG main updateByPrimaryKeySelective - ==> Parameters: 2017-12-22 17:27:19.579(Timestamp), 1049(Long) 2017-12-22 17:27:30,033-[TS] DEBUG main updateByPrimaryKeySelective - <== Updates: 1发现在Mybatis这一层,精度是传递下去了;
所以去Debug下,看看到底在哪一行把这精度给搞丢了,当我们一步步跟到MySQL JDBC Driver这一个方法时,发现:
private synchronized void setTimestampInternal(int parameterIndex, Timestamp x, Calendar targetCalendar, TimeZone tz, boolean rollForward) throws SQLException { if(x == null) { this.setNull(parameterIndex, 93); } else { this.checkClosed(); if(!this.useLegacyDatetimeCode) { this.newSetTimestampInternal(parameterIndex, x, targetCalendar); } else { String timestampString = null; Calendar sessionCalendar = this.connection.getUseJDBCCompliantTimezoneShift()?this.connection.getUtcCalendar():this.getCalendarInstanceForSessionOrNew(); synchronized(sessionCalendar) { x = TimeUtil.changeTimezone(this.connection, sessionCalendar, targetCalendar, x, tz, this.connection.getServerTimezoneTZ(), rollForward); } if(this.connection.getUseSSPSCompatibleTimezoneShift()) { this.doSSPSCompatibleTimezoneShift(parameterIndex, x, sessionCalendar); } else { synchronized(this) { if(this.tsdf == null) { this.tsdf = new SimpleDateFormat("\'\'yyyy-MM-dd HH:mm:ss\'\'", Locale.US); } timestampString = this.tsdf.format(x); this.setInternal(parameterIndex, timestampString); } } } this.parameterTypes[parameterIndex - 1 + this.getParameterIndexOffset()] = 93; } }此处有一个格式化代码,将时间对象都以’yyyy-MM-dd HH:mm:ss’形式给处理了,自然将我们的毫秒数给抛弃了,此时查看我们的JDBC Driver版本,是5.1.19,难道数据库支持毫秒而驱动不支持?不太可能,所以怀疑是我们的驱动版本过低,因为支持毫秒的特性是MySQL 5.6.4开始有的,所以将JDBC Driver升级一下,这里我用的5.1.39,再跑一遍程序,毫秒数已经可以插入到数据库,再次Debug下,可以看到在相同的方法中,MySQL已经加上了毫秒数的支持:
if (this.connection.getUseSSPSCompatibleTimezoneShift()) { doSSPSCompatibleTimezoneShift(parameterIndex, x); } else { synchronized (this) { if (this.tsdf == null) { this.tsdf = new SimpleDateFormat("''yyyy-MM-dd HH:mm:ss", Locale.US); } StringBuffer buf = new StringBuffer(); buf.append(this.tsdf.format(x)); if (this.serverSupportsFracSecs) { int nanos = x.getNanos(); if (nanos != 0) { buf.append('.'); buf.append(TimeUtil.formatNanos(nanos, this.serverSupportsFracSecs, true)); } } buf.append('\''); setInternal(parameterIndex, buf.toString()); // SimpleDateFormat is not // thread-safe } }其实就是判断一下数据版本,如果支持毫秒精度特性,就把毫秒数加上;
解决
上边排查到原因,解决方法就好了,直接升级更新的驱动版本;
思考
其实这种问题在日常开发中很常见,保持一颗刨根问底的心很重要,太阳底下无新事、源码之下无黑盒,一步步追踪下去,会找到问题所在的。
-
Github-没有做不到-只有想不到

背景
体验过Github的几个产品,感觉开发Github的这批人真的很富有想像力;原来一个托管代码的网站还能这么玩:没有做不到、只有想不到;
所以今天我来谈谈Github的创新;
Github能做什么
提起Github,可能大家第一印象便是:
1. 不就一个托管代码网站么; 2. 顺便存储些文件、图片,还能当一个网盘用; 3. 可以在上面找些开源工具来用; 4. 不注册一个Github账号,都不好意思跟别人打招呼; 5. 程序猿交友网站(同性)对,上边理解都有一定道理;要说Github的创新,我们来看看Github给我们提供了哪些产品?
1. 写代码、托管代码,这点不用多说,但是Github一出场就能远甩SourceForge几条街,仅仅是因为它支持Git这个工具么? 2. 写博客,什么,这不是WordPress这类软件做的事情么?你竟然用Github写博客,不好意思,Github真的可以,并且能让你像写代码一样写博客,让博客回归写作本质; 3. 代码片段,这是什么东东?对不起,它有个正式的名字叫:Gist,我们稍后会介绍; 4. 编辑器,当你还在讨论神用的编辑器和编辑器之神的时候,Github告诉我们,其实你还有另一种选择,Sublime?No No No,虽然它长的很像Subline,它有正式名字叫:Atom; 5. 电子书,这TM不是epub、mobi之流的特长么,你敢说Github也支持?不错,Gitbook,写电子书,为你而来; 6. 工具市场,什么?Github要卖东西,不错,如果你需要一些工具,可以直接到市场里去买,对于一些小创公司来说,节省成本,正如Github MarketPlace宣传视频里所说那样; 7. Bug追踪,你是在逗我么?我们公司明明有用开源的BugFree软件,且慢,先来看看Github的Issues; 8. StackOverFlow,神经病吧,这不是我们程序猿写代码的灵感源泉么?Github也有这功能,有没有我不知道,总之以前技术难题都去stackoverflow上查,现在发现有些难题得去Github上查; 9. 招聘,你是想逼疯HR么,Github说:我也不想的,只是有HR这么干,从Github上找候选人,怪我喽? 10. 在线简历,行行行,I服了You,你到底还有哪些事情不能做? 11. . . . . . .别着急,且听我慢慢给你道来。
代码托管
曾几何时,代码托管不是SourceForge、GoogleCode这类产品的天下么,怎么突然出来一个Github,把市场搅的天翻地覆,如果仅仅做为支持Git工具的角度来看,Github还真不比前边那些网站有优势,毕竟人家要么家大业大、要么起步早积累厚,但是Github不跟你们拼这些,Github说:我除了长像小清新、支持版本控制工具Git外,我还支持PR、Fork等功能,我还是代码网站中的微博、我能让程序猿们Follow他们喜欢的猿、我让用户有粘性,你要硬说我是程序猿交友网站,我也不反对;当你们还在苦苦力拼谁支持的免费空间更大、更长的时候,我玩的是社交,懂么?要想有粘性、得靠互动、得有社交;这时候是来看一下这张网站流传的图了:

在代码托管的领域里,Github说:我先行一步,你们这些老古董们慢慢追。
写博客
既然代码能托管,那么文章为啥就不能托管呢?能、能、能,Github Pages就是干这个的;你可以用你喜欢的任一款编辑器写完文章,Push到Github便可,此时文章便可访问。
什么?这么简单?难道不需要租得VPS、建数据库、搭Nginx、买域名?用WordPress五分钟建站、或者直接上AWS套餐不也也简单么?如果你觉得网站版富文本编辑器好用,那我也无话可说。
用过多款建站工具之后,Github Pages这类静态模板网站,真的是专为开发人员而设;不错,本站正是用Github Pages,Fork一个你喜欢的代码仓库,便可以开始写博客了。
当然,如果非开发人员,只要你会Git几个命令,上手也很简单;
代码片段
如果你平时需要将一些片段代码保存、留待后用、查看,那么试试Gist,比如这个场景:开发人员在写文章的时候,要在文章中嵌入一些代码片段,用Gist就恰好,看下边这段代码:
如果你所在网络不能访问Gist,看截图:

编辑器
如果你用过Sublime,那么看到Atom,你会觉得很亲切;对js、Node同学是另一种不错的选择;畅想一下,加上Github的托管功能,Atom是不是就一个Evenote、云笔记?另加上强大的插件功能、原来的一些单体应用比如Mou是不是可以退休了?
Atom是想发展成程序猿日常工具的全家桶么?

电子书
如果你经常看技术文章,那么对Gitbook形式的电子书一定不陌生;也有很多开源项目的文档就用Gitbook来写,比如TensorFlow;
当然,你如果想用Gitbook写日记、写博客,也没人反对;
工具市场
工具市场有什么用呢?直接上官方宣传视频,一眼明了;

现在市场里已经有Travis CI、Sentry等工具可用,这完全是模仿App Store的套路来的;
问题追踪
如果你有一个开源项目,别人有问题,可以用Issues给你提,是像Jira Task?还是像BugFree?还是像论坛留言板?你说像什么就像什么吧?反正用着挺爽;
如果大家都针对相应的技术问题用Issues讨论,那么StackOverFlow是不是感觉有点小危机?
如果一个人在Issues回答的问题质量又高、又多,是不是可以称得上大V?是不是也可以开一堂Github Live?
其它
用Github做一张简历?Resume
HR在上面筛选简历?
当然还有很多功能我没写出来的、也会一直不断有新功能加进来;
体会
能把一个代码托管网站玩出这么多花样,你能想得到么?
两岸猿声啼不住, 轻舟已过万重山.
-
Java多线程系列-JCU-API实现

背景
接着上一篇《Java多线程系列-增加工作线程-线程池》,Java Concurrent包提供了一些API,怎么用呢;
需求
- 用JUC包提供的互斥、锁机制去改造我们的WebServer;
功能开发
JUC包提供了Lock相关类用来替代synchronized关键字(线程间互斥),提供了Condition来替代wait、notify方法(线程间通信);
我们用Lock、Condition来改造下阻塞队列;加入一个lock-队列本身的锁、一个写线程Condition、一个读线程Condition;如下:
// 共享变量锁 private Lock lock = new ReentrantLock(); // 写线程的条件 private Condition putCondition = lock.newCondition(); // 读线程的条件 private Condition takeCondition = lock.newCondition(); public SimpleQueue(int cap) { this.capacity = cap; this.items = new Object[cap]; this.size = 0; this.putIndex = 0; this.takeIndex = 0; } public void put(E e) throws InterruptedException { lock.lock(); try { // 监听器线程往队列中放入socket,如果当前队列满了则监听器等待 while (isFull()) { Logs.SERVER.info("{} wait put queue : {}", Thread.currentThread().getName(), e); putCondition.await(); } // 若队列没满,则监听器线程往队列中放入socket;并且如果先前已经有工作线程在等待取数据,通知工作线程来取 items[putIndex] = e; putIndex = (putIndex + 1) % capacity; size++; Logs.SERVER.info("queue isFull {}, isEmpty {}, capacity {}, size {}, takeIndex {}, putIndex {}", isFull(), isEmpty(), capacity, size, takeIndex, putIndex); takeCondition.signalAll(); } finally { lock.unlock(); } } public E take() throws InterruptedException { // 工作线程来取socket,如果当前队列为空,则工作线程进行等待 lock.lock(); try { while (isEmpty()) { Logs.SERVER.info("{} wait get socket", Thread.currentThread().getName()); takeCondition.await(); } // 队列不为空,工作线程从队列中取出socket;并且如果先前有监听器线程在等待往队列中放数据,通知监听器线程放 E e = (E) items[takeIndex]; // 将已经取走的引用置为空,让GC可以回收 items[takeIndex] = null; takeIndex = (takeIndex + 1) % capacity; size--; Logs.SERVER.info("queue isFull {}, isEmpty {}, capacity {}, size {}, takeIndex {}, putIndex {}", isFull(), isEmpty(), capacity, size, takeIndex, putIndex); putCondition.signal(); return e; } finally { lock.unlock(); } }完整代码实现:WebServer.java
知识点
对于解决线程间互斥、通信两个问题,至此我们用了两种方式,也即Java给出的两套方案,我们的程序逻辑没变,只是换一种方式去实现而已;
其实掌握了其中的思想,剩下的就是查API去实现逻辑,我认为的多线程编程两个主要问题点:互斥、通信,出现这两个问题的关键在于:共享变量,如果没有共享变量,都是线程本地变量,那么就不会存在资源冲突、通信了;打个比方:公司只一台跑步机,所有人都可以用、每个人就是一个线程,而跑步机便是共享变量,A同学在使用跑步机、那个其它同学就只能等待,这就是互斥,如果A用完、告诉B同学你可以使用了,这就叫通信;如果说每人一台跑步机,每个人的跑步机都是自己独享的,就不存在互斥、通信了,因为根本没有竞争;
想明白多线程问题的上下文就不会觉得多线程不好掌握了,其实和我们日常生活中的道理一致,只是苦于一些书籍写的太抽象、不接地气,导致我们理解因难,大道至简;
问题
JUC其实除了Lock、Condition,还给我们提供了很多工具类,比如线程池、Atomic包等,可以极大方便我们平时应用;
当然我们的线程池完全可以用ExcutorService替换掉,我们的队列完全可以也BlockingQueue替换掉;
感想
人生经历的过程的,就是不断认识自己不足、一点点改进的过程;
-
Java多线程系列-增加工作线程-线程池
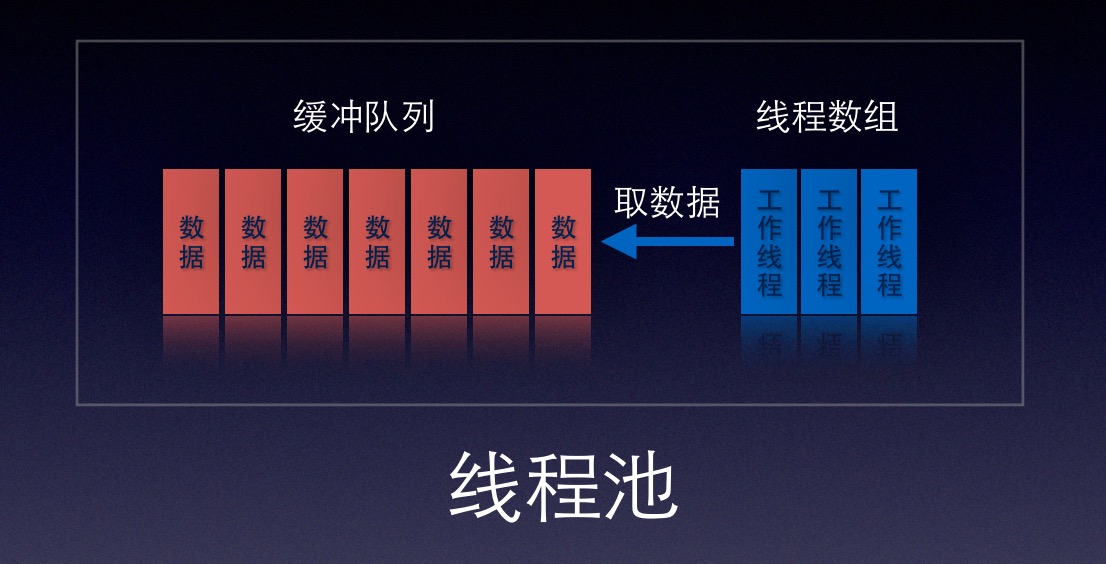
背景
接着上一篇《Java多线程系列-缓解忙等问题》我们提出的问题,工作线程过多,我们要多加一些线程参与处理任务;
需求
- 增加工作线程数量,一个线程处理任务太慢、太苦逼、太寂寞,有活大家一起干;
功能开发
简单做
简单点做,直接将原来的一个线程变量改一个线程数组,直接上代码:
// 处理HTTP请求线程组 private Worker[] workers; /** * 必需先启动工作线程,再启动监听线程. */ private void start() { // 启动工作线程,工作线程,可以作为守护线程 int poolSize = 2; workers = new Worker[poolSize]; for (int i = 0; i < poolSize; i++) { workers[i] = new Worker(i); } Logs.SERVER.info("start workerPool size : {} ...", poolSize); // 启动监听线程,监听线程,不作为守护线程,保证JVM不退出. acceptorThread = new Thread(new Acceptor()); acceptorThread.setName("http-acceptor-" + port + "-thread"); acceptorThread.start(); Logs.SERVER.info("start acceptor thread : {} ...", acceptorThread.getName()); }完整代码实现:WebServer.java
小重构
现在我们的WebServer可以由多个工作线程处理任务了,不过WebServer所担任的责任有些杂了,其实可以将workers和queue组合起来(组合模式)抽象为一个线程池,工作机制便是监听器线程往线程池中放任务,线程池自己去队列里取任务;
此处我再进行一次小重构,看代码:
/** * 一个简单的固定大小线程池,数组实现,任务先放入阻塞队列,工作线程不断去队列中取任务. */ public class ThreadPool { // 监听到的socket队列 private SimpleQueue<Socket> socketQueue; // 线程组 private Worker[] workers; public ThreadPool(int poolSize) { this.socketQueue = new SimpleQueue<>(3); workers = new Worker[poolSize]; for (int i = 0; i < poolSize; i++) { workers[i] = new Worker(this, i); } Logs.SERVER.info("start workerPool size : {} ...", poolSize); } /** * 由监听线程往队列中放入socket,以备工作线程从中取值进行处理. */ private void assign(Socket socket) throws Exception { socketQueue.put(socket); } /** * 工作线程从队列中取出socket. */ private Socket await() throws Exception { return socketQueue.take(); } }完整代码实现:WebServer.java
知识点
这次,细心的同学已经发现,我们不能再用notify方法了,改成notifyAll方法了,为什么呢?因为同时等待的工作线程是多个;
还有一个细节是,列队take、put方法开始的判断队列是否为空、是否满的逻辑由原来的if变成了while,想想这是为什么?
问题
到这一版,有同学抱怨了,你不是说Java还有JUC的实现方案么,OK,下一版我们就用JUC中的工具去实现:
感想
我们现在已经有了一个WebServer的雏形了,想做的完善就一步步迭代,比如想支持Servlet规范,那么再将Socket包装成Request、Response对象,实现Servlet规范便可;
这段时间经常听到中年危机,都说编程是吃年轻饭,太长远我也看不到,做一天是一天,躲进小楼成一统、管他春夏与秋冬。
-
Java多线程系列-缓解忙等问题
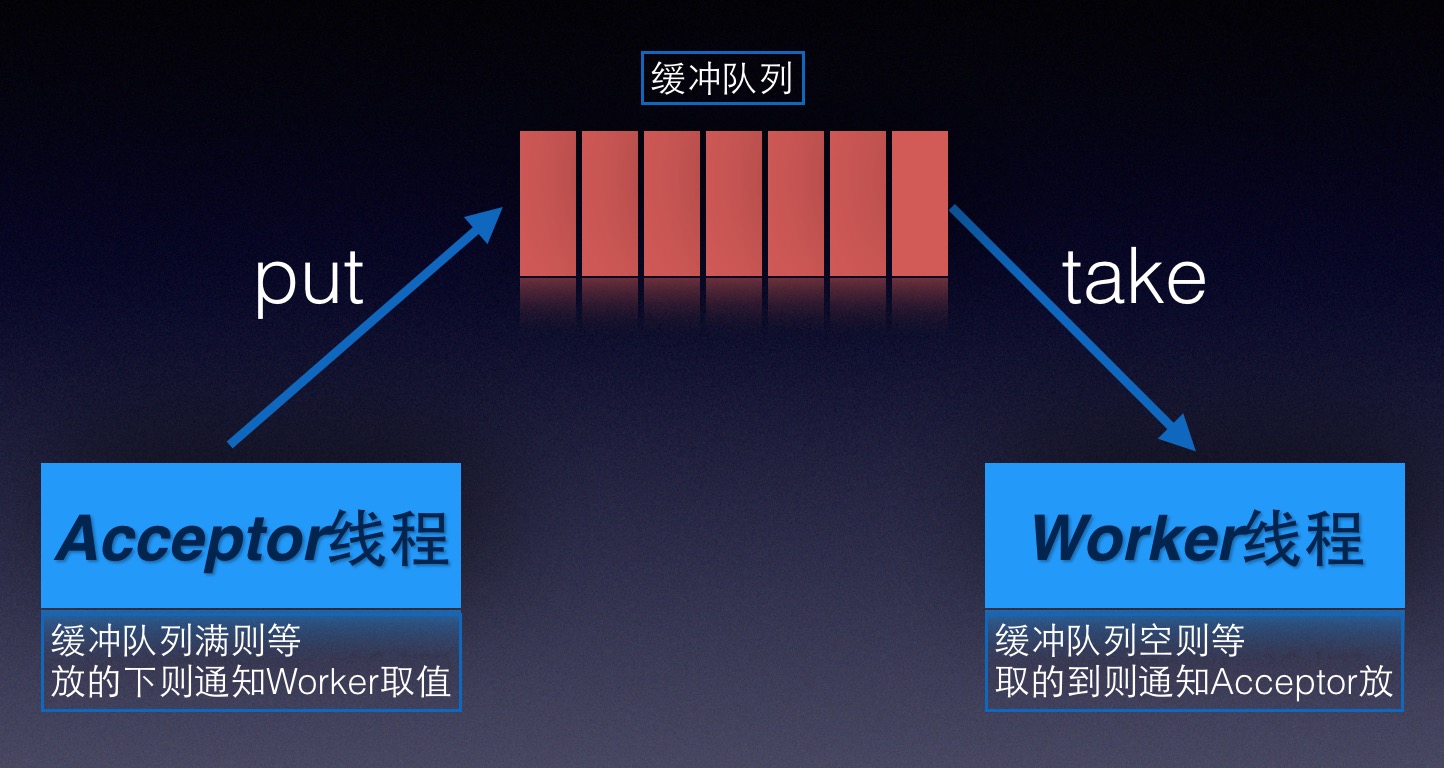
背景
接着上一篇《Java多线程系列-开始给工作线程减压》我们提出的问题,监听器线程会一直等待工作线程处理完一个socket后,再去接收下一个socket,为了缓解这个问题,我们引入了缓冲队列,简单说:就是将上一节当中的共享变量WebServer.socket换成一个队列,这样我们监听器接收完socket往队列里放、不再直接依赖工作线程处理完,貌似还真的是计算机中的所有问题都可以通过引入一个中间层去解决;
打个比方:我们的餐馆有了一个前台接待(监听器线程)、一个厨师兼职传菜(工作线程),只有一个位置(共享变量),当前台接待一名用户进来后,用户将这个位置占了,厨师也开始忙活了,此时前台又接待了一个新用户,只能告诉新用户:只有一个位置已经有人了,麻烦您等会;现在我们想同时接待多个用户,采用的一个办法就是添加位置(队列),这样前台接待一位用户便可以将其安排在空闲的位置了(队列);
需求
- 通过引入一个阻塞队列,来缓解监听器线程忙等的问题;
功能开发
这一版我们并没引入线程新的知识点,只是自己动手写了一个简单的阻塞队列;
阻塞队列
一个简单的阻塞队列:先进先出,线程安全,不支持扩容,用数组实现.
/** * 一个简单的阻塞队列(先进先出),线程安全,不支持扩容,用数组实现. */ public class SimpleQueue<E> { // 元素数据 private Object[] items; // 队列容量 private int capacity; // 队列头索引 private int putIndex; // 队列尾索引 private int takeIndex; // 队列当前元素个数 private int size; public SimpleQueue(int cap) { this.capacity = cap; this.items = new Object[cap]; this.size = 0; this.putIndex = 0; this.takeIndex = 0; } public synchronized void put(E e) throws InterruptedException { // 监听器线程往队列中放入socket,如果当前队列满了则监听器等待 if (isFull()) { Logs.SERVER.info("{} wait put queue : {}", Thread.currentThread().getName(), e); wait(); } // 若队列没满,则监听器线程往队列中放入socket;并且如果先前已经有工作线程在等待取数据,通知工作线程来取 items[putIndex] = e; putIndex = (putIndex + 1) % capacity; size++; Logs.SERVER.info("queue isFull {}, isEmpty {}, capacity {}, size {}, takeIndex {}, putIndex {}", isFull(), isEmpty(), capacity, size, takeIndex, putIndex); notify(); } public synchronized E take() throws InterruptedException { // 工作线程来取socket,如果当前队列为空,则工作线程进行等待 if (isEmpty()) { Logs.SERVER.info("{} wait get socket", Thread.currentThread().getName()); wait(); } // 队列不为空,工作线程从队列中取出socket;并且如果先前有监听器线程在等待往队列中放数据,通知监听器线程放 E e = (E) items[takeIndex]; // 将已经取走的引用置为空,让GC可以回收 items[takeIndex] = null; takeIndex = (takeIndex + 1) % capacity; size--; Logs.SERVER.info("queue isFull {}, isEmpty {}, capacity {}, size {}, takeIndex {}, putIndex {}", isFull(), isEmpty(), capacity, size, takeIndex, putIndex); notify(); return e; } public synchronized boolean isFull() { return capacity == size; } public synchronized boolean isEmpty() { return size == 0; } }如果你所在的网络能访问Gist,这个格式可能更友好:
完整代码实现:WebServer.java
知识点
因为我们的队列是线程安全的,所以WebServer.assign和await方法便无需再加synchronized的关键字了;
在队列中的通知方法依旧用的notify方法,为什么不用notifyAll方法呢?因为监听器线程(生产者线程)只有一个、工作线程(消费者线程)也只有一个;
还有个细微点要注意的就是:synchronized关键字上一节也用到了,但是和本节的synchronized关键字所表示的锁对象是不一样的,上一节WebServer拥有一个Socket变量,的锁对象是WebServer、由WebServer自己控制同步、阻塞,而本节使用了队列,锁对象是加在队列上的;
/** * 由监听线程往队列中放入socket,以备工作线程从中取值进行处理. */ private void assign(Socket socket) throws Exception { socketQueue.put(socket); } /** * 工作线程从队列中取出socket. */ private Socket await() throws Exception { return socketQueue.take(); }问题
到这一版,我们已经缓解了监听器线程忙等问题,但是还存在问题:
- 若监听器线程的接收速度要快于工作线程的速度,那么队列就会处理不及时,等队列满了之后还会存在监听器线程忙等;
感想
今天上班地铁上,看到一首诗,白居易的,人生时起时落,努力学会淡然:
《风雨晚泊》
苦竹林边芦苇丛,停舟一望思无穷。
青苔扑地连春雨,白浪掀天尽日风。
忽忽百年行欲半,茫茫万事坐成空。
此生飘荡何时定,一缕鸿毛天地中。