柒八块表的博客
-
Java多线程系列-开始给工作线程减压
背景
接着上一篇《Java多线程系列-开始给主线程减压》我们提出的问题,工作线程做了所有的事情,不够专注,就好比我开了一家餐厅,我即当前台接待用户、又当厨师烧菜、又当服务员上菜,等一个用户结账走人后再去接待下一个用户,只有我这一个线程去忙活,苦逼啊,这次,我们就雇一个员工替我分单压力,即再创建一个新的线程去工作。
需求
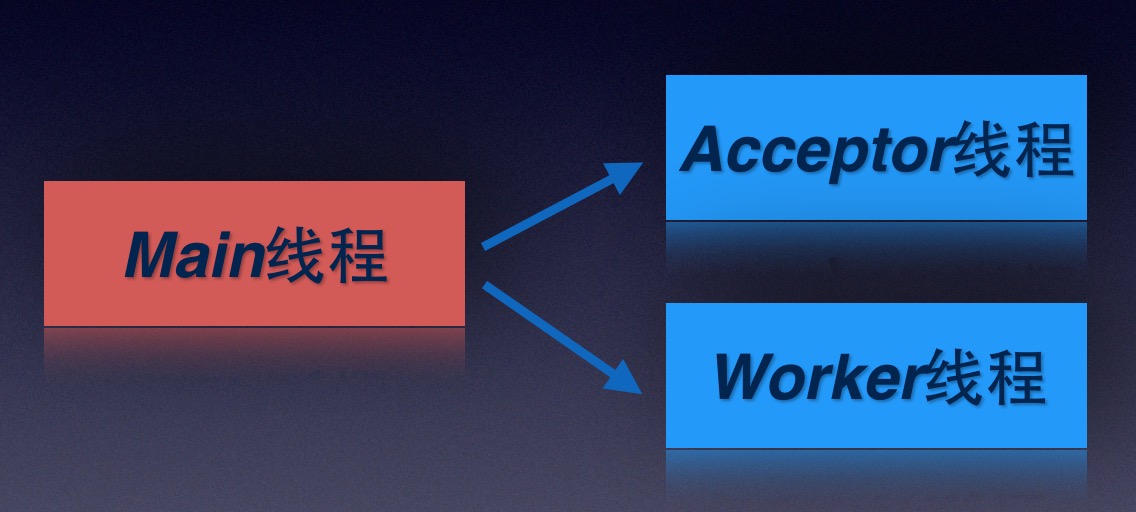
- 新开一个线程,专门用来监听8080端口,监听到有新的请求Socket后,将Socket交给工作线程去处理请求,这个新的线程我们命名为Acceptor-接收器;
- 工作线程只处理Socket请求,不做监听的事情;
功能开发
这一版我们开始接触线程的一些新知识点:比如引入了共享变量、线程通信,当然也会用synchronized关键字,因为有两个线程,就涉及到对共享变量的读写;
加入监听线程
Acceptor-专门监听端口接收Socket,将接收到的Socket交给工作线程处理;
/** * 必需先启动工作线程,再启动监听线程. */ private void start(WebServer server) { // 启动工作线程,工作线程,可以作为守护线程 workerThread = new Thread(new Worker()); workerThread.setName("worker-process-thread"); workerThread.setDaemon(true); workerThread.start(); Logs.SERVER.info("start worker thread : {} ...", workerThread.getName()); // 启动监听线程,监听线程,不作为守护线程,保证JVM不退出. acceptorThread = new Thread(new Acceptor()); acceptorThread.setName("http-acceptor-" + port + "-thread"); acceptorThread.start(); Logs.SERVER.info("start acceptor thread : {} ...", acceptorThread.getName()); } /** * 接收器,监听HTTP端口,接收Socket. */ public class Acceptor implements Runnable { @Override public void run() { try { while (!isStop) { Logs.SERVER.info("acceptor begin listen socket ..."); Socket socket = listen(); Logs.SERVER.info("acceptor a new socket : {}", socket); assign(socket); } } catch (Exception e) { Logs.SERVER.error("Acceptor process error", e); } } }如果你所在网络能访问Gist,那么下边这块代码看起来应该更友好:
完整代码实现:WebServer.java
工作线程
工作线程不再监听端口,只去一个固定的地方取Acceptor收到的Socket,这个固定的地方,我们暂时用一个成员变量存储;
/** * 处理HTTP请求的工作者. */ public class Worker implements Runnable { @Override public void run() { try { while (!isStop) { Socket s = await(); if (s != null) { Logs.SERVER.info("worker begin process socket : {}", socket); process(s); socket = null; } } } catch (Exception e) { Logs.SERVER.error("Worker process error", e); } } }知识点
守护线程
工作线程,将其置为守护线程,让它在后台慢慢运行就可以了;
监听器线程,我们将其置为非守护线程,那守护线程和非守护线程有什么区别吗?我们来看下Java Thread中setDaemon方法的说明:
Marks this thread as either a {@linkplain #isDaemon daemon} thread or a user thread. The Java Virtual Machine exits when the only threads running are all daemon threads. This method must be invoked before the thread is started.
如果JVM中所有的线程都是守护线程了,那么JVM就会退出,所以为了不让JVM退出,至少需要有一个非守护线程,这里便是监听器线程;
线程互斥
我们的共享变量会由两个线程去操作,监听器线程去写、工作线程去读,如果在写到一半的时候CPU切换到工作线程去读,那么可能读到的数据为空,所以要保证此处对共享变量的读写都是原子操作,这便是synchronized关键字的作用;
线程通信
此版本涉及两个线程:监听器线程和工作线程,并且这个两个线程是有依赖关系的,即监听器线程先要收到一个Socket,然后再将这个Socket给工作线程,工作线程去处理,这就引出了不同线程之间的通信问题,此处通过一个共享变量来实现,即监听器线程拿到Socket后、交给WebServer.socket变量,然后工作线程从WebServer.socket变量上取值,从这里,你可能已经看到相似的场景了,一个线程接收数据(Socket)、一个线程获取数据(Socket)、有一个地方(共享变量)存储数据,这不是典型的生产者、消费者模型么?别急,这个后边会讲到,此处还是按简单的方式来处理;
线程通信,Java提供的一种方案是wait/nofity机制,我们此处正是用的这种方案:
- 监听器线程取到Socket后,往共享变量赋值,如果此时共享变量有之前已经赋过的值还没被工作线程取走,那么监听线程就先等待(wait),如果此时之前赋值的Socket被工作线程取走后、工作线程通知监听器线程可以去赋值了;
- 工作线程去取Socket时,如果此时共享变量还没有被监听器线程去赋值,那么工作线程就先等待(wait),如果此时共享变量已经被监听器线程赋值,那么工作线程直接取值即可、并会通知在等待的监听器线程可以再次进行赋值(如果此时监听器线程接收到新的Socket);
一图胜千言,来看下这个过程:

再来看下我们的代码,注释的已经很清楚了:
/** * 由监听线程给socket赋值,以备工作线程从中取值进行处理. */ private synchronized void assign(Socket socket) throws Exception { // 监听器线程给socket变量赋值,如果当前socket可用(即已经被赋过值还没被工作线程取走),则监听器线程进行等待 while (available) { Logs.SERVER.info("{} wait assign socket : {}", Thread.currentThread().getName(), socket); this.wait(); } // 若socket状态不可用,则监听器线程赋值成功;并将状态置为可用,因为此时socket已经有值,可以让工作线程来取 this.socket = socket; available = true; // 上边赋值成功后,监听器线程通知在等待的工作线程可以来取socket了 this.notify(); } /** * 工作线程取出当前的socket. */ private synchronized Socket await() throws Exception { // 工作线程来取socket,如果当前socket不可用(即socket还没有被赋值),则工作线程进行等待 while (!available) { Logs.SERVER.info("{} wait get socket", Thread.currentThread().getName()); this.wait(); } // socket可用,则工作线程取到socket;并将状态置为不可用,因为工作线程已经取走 Socket socket = this.socket; available = false; // 工作线程通知监听器线程:现在socket对象已被取走,监听器线程可以再去给socket赋值了 this.notify(); return socket; }注意此处通知用的nofity,还一个notifyAll方法为什么不用呢?因为读线程只有一个、写线程也只有一个,所以用notify就够了,如果读写线程有多个,那么我们就得用notifyAll了;
问题
到这一版,我们已经实现监听器线程和工作线程的分离,使其各司其职,但是还存在着问题:
- 请求依旧是串行化处理,因为即使监听器线程接收多个Socket,但是工作线程只有一个,工作线程处理一个Socket,监听器线程才能放下一个,其实监听器线程会出现忙等;
感想
遇到问题、解决问题,其实一些事情并没有想像中的复杂,当我们不了解的时候,只因我们没有遇到那个场景;
纸上得来终觉浅,绝知此事要躬行,动动手,一行一行自己写出来,去debug,便了解的更透彻;
-
Java多线程系列-开始给主线程减压

背景
接着上一篇《Java多线程系列-先写一个简单WebServer》我们提出的问题,main线程做了所有工作,为了更好的处理请求,我们给main线程减压,加入一个工作线程分担main线程处理HTTP请求的任务,让main线程只做一些准备性的工作,比如:准备启动参数、环境变量等等.
需求
- 创建一个工作线程去处理HTTP请求,将main线程做的事情和工作线程做的事情分离;
- 随着功能的完善,采用面向对象的思想去组织我们的代码,抽象出一些概念;而不是像V1版本所有的代码都放在一个类中;
功能开发
加入工作线程
此时,开始进入Java Thread编程了。
主要代码如下:
/** * 启动处理线程. */ private void start(BootstrapV2 server) { logicThread = new Thread(new Worker(server)); logicThread.setName("logic-process-thread"); logicThread.start(); } /** * 处理HTTP请求的工作者. */ public class Worker implements Runnable { private BootstrapV2 server; public Worker(BootstrapV2 server){ this.server = server; } @Override public void run() { server.serve(); } }完整代码实现:BootstrapV2.java
做个重构
随着功能的不断完善,代码量也越来越多,将所有代码耦合在一个类中显然不是一个好方法,这一版当中我们采用面向对象的思想去做个重构,关键点:职责单一;
Bootstrap-启动器
启动器,只做WebServer启动的工作,比如准备参数、环境变量、启动工作线程等,不做具体处理HTTP请求的任务;
完整代码实现:Refactor
/** * Created by junweizhang on 17/11/21. * 第二版 WebServer 重构,将main线程和服务线程分离. * 抽象出三个角色: * Bootstrap-启动器 * WebServer-Web服务器 * Worker-处理HTTP请求的工作者. */ public class Bootstrap { /** * 我是启动器,只做参数初始化等相关工作. * @param args */ public static void main(String[] args) { try { int port = 8080; String docRootStr = "htmldir"; URL url = Bootstrap.class.getClassLoader().getResource(docRootStr); File docRoot = new File(url.toURI()); WebServer webServer = new WebServer(port, docRoot); Logs.SERVER.info("init webServer : {}", webServer); Logs.SERVER.info("我是main线程, 好开心, 我已经被释放出来了, 可以做些其它的事情..."); } catch (Exception e) { Logs.SERVER.error("main start error", e); System.exit(1); } } }WebServer-Web服务器
WebServer,负责WebServer对外提供HTTP的服务,比如持有ServerSocket、将具体任务的执行代理给工作线程等;
public class WebServer { private ServerSocket ss; private File docRoot; private boolean isStop = false; // 处理HTTP请求线程 private Thread logicThread; public WebServer(int port, File docRoot) throws Exception { // 1. 服务端启动8080端口,并一直监听; this.ss = new ServerSocket(port, 10); this.docRoot = docRoot; start(this); } /** * 启动处理线程. */ private void start(WebServer server) { logicThread = new Thread(new Worker(server)); logicThread.setName("logic-process-thread"); logicThread.start(); } ... }Worker-处理HTTP请求的工作者
Worker,工作者,监听8080端口,处理HTTP请求,这里我将其作为WebServer的内部类;
/** * 处理HTTP请求的工作者. */ public class Worker implements Runnable { private WebServer server; public Worker(WebServer server){ this.server = server; } @Override public void run() { server.serve(); } }问题
到这一版,我们已经实现main线程和工作线程的分离,使其各司其职,但是还存在着问题:
- 工作线程还是既监听8080端口,又处理HTTP请求;
- 因为工作线程做的事情太多,所以效率不高,请求依旧是串行化处理;
感想
经过这一版,代码相对来说清晰一些了,并且也开始接触Java Thread编程了,虽然只是简单的new Thread(),慢慢来;
-
Java多线程系列-先写一个简单WebServer

背景
想通过实际场景来介绍下多线程的应用,思来想去,就以开发一个Demo版的Web容器为例子来讲一下吧,这里面会用到线程池、线程通信、线程同步等知识点,能把多线程用到的知识点给贯穿起来;
需求
先来看看需求背景,我们要开发一个Web容器,满足以下功能:
- 支持静态文件的访问:比如html jpg js等;
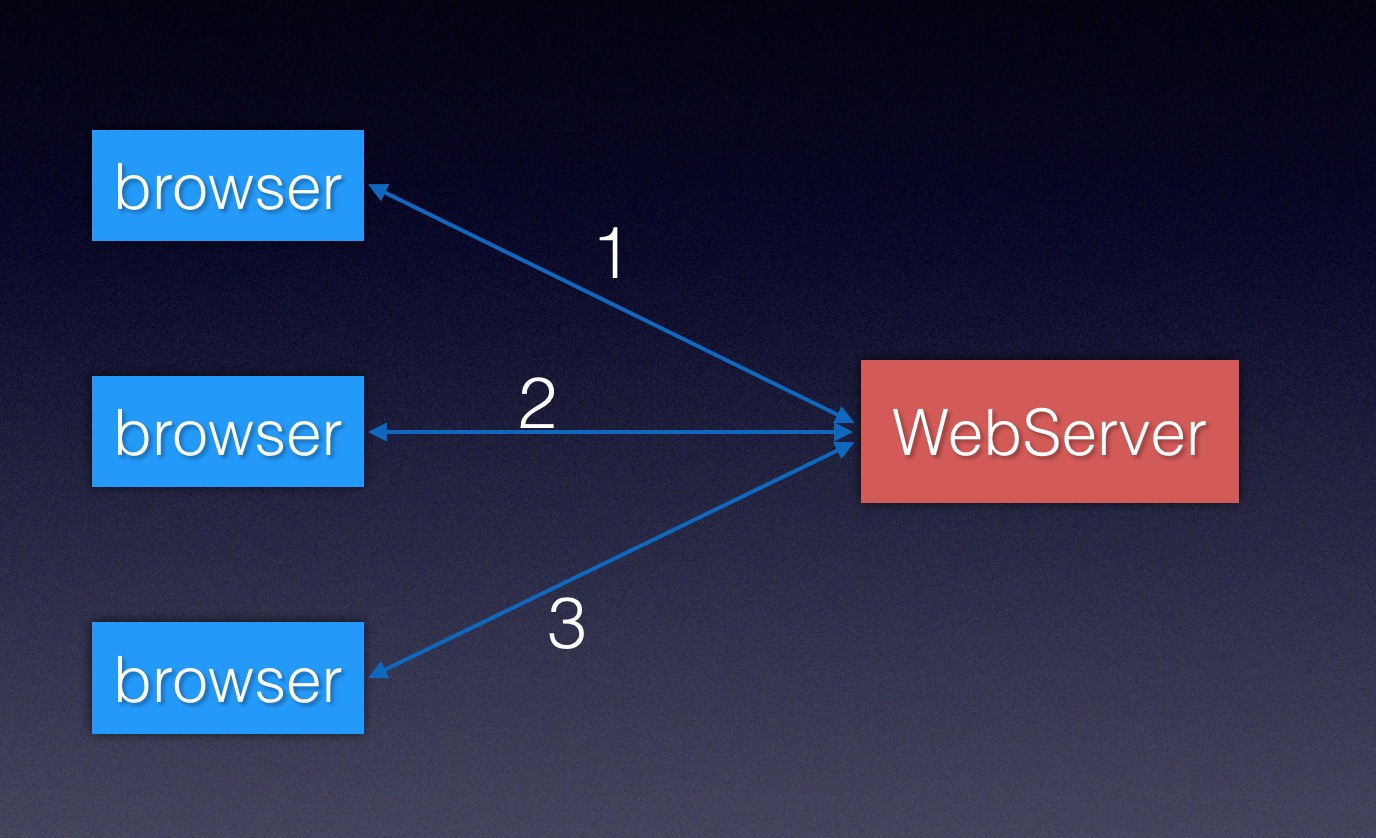
- 支持静态文件的并发访问:因为一个界面上往往有很多资源,比如一个网页除了index.html文件之外、网页内还会有引入一些js、图片等资源,如果请求都是串行处理(即请求完index.html,再一个一个请求js文件、图片文件),用户浏览体验差;
- 支持HTTP/1.1协议;
- 当然,因为是Demo,只是为了学习多线程编程,我们不过多的考虑性能、扩展性;
需求场景如下图:
功能开发
单线程版
了解了以上需求,先进行简单的功能开发,先回顾下如何实现一个简单的WebServer;
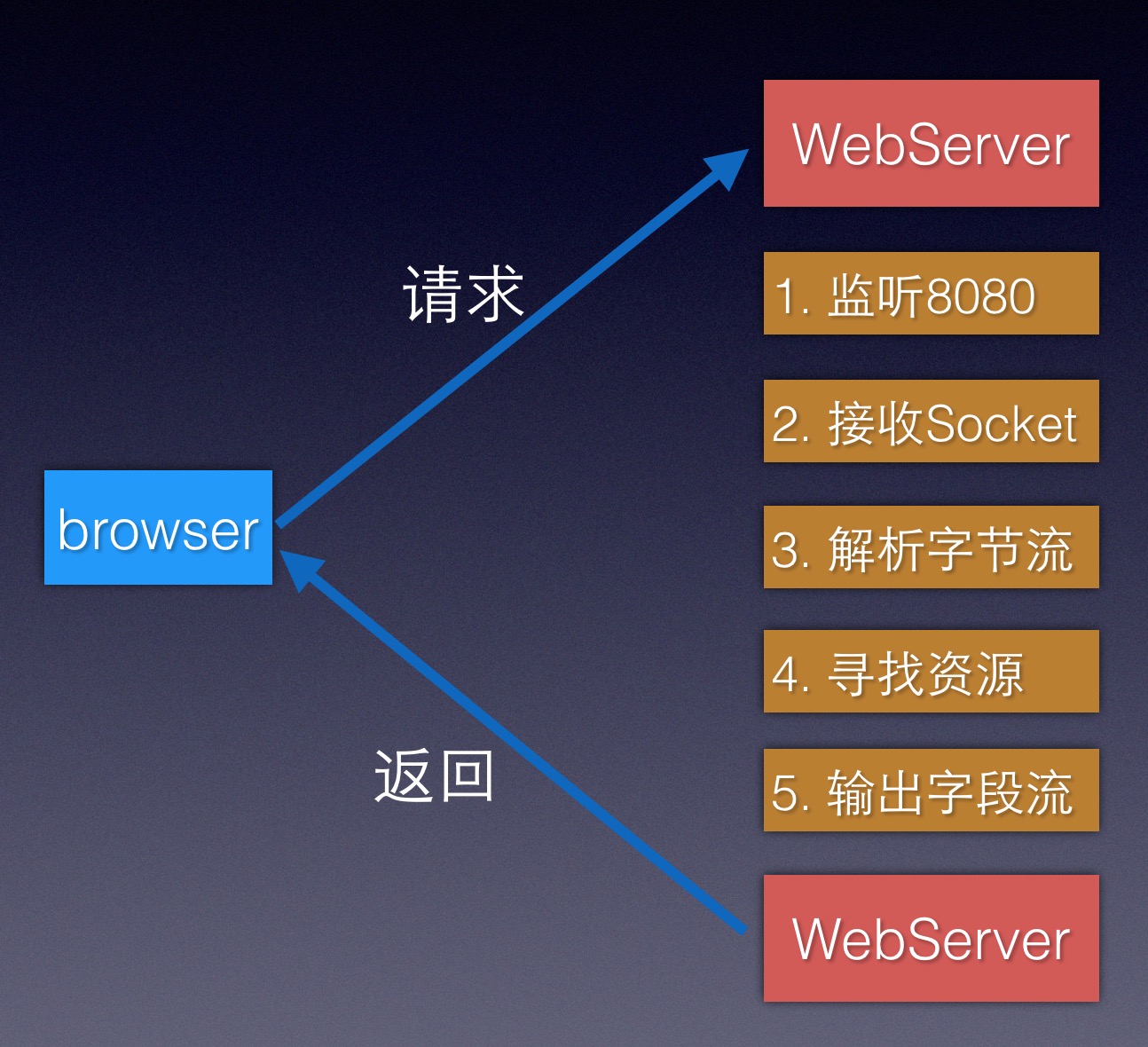
当用户从浏览器输入一个地址,比如:http://localhost:8080/,其实是请求到WebServer的机器并且连接上8080端口,告诉WebServer,请求方法为GET、请求路径是/(根路径),告诉WebServer,如果你能找到这个请求对应的资源,那么按HTTP协议格式给我返回,如果你找不到,也按照HTTP协议格式给我返回,明白了WebServer接收一个浏览器请求的过程,我们来梳理下这个过程,如下:
- 服务端启动8080端口,并一直监听;
- 监听到有客户端(比如浏览器)要请求http://localhost:8080/,那么TCP三次握手,建立连接;
- 建立连接后,读取此次连接客户端传来的内容(其实就是解析网络字节流并按HTTP协议去解析);
- 解析到请求路径(比如此处是根路径),那么去根路径下找资源(比如此处是index.html文件);
- 找到资源后,再通过网络流将内容输出,当然,还是按照HTTP协议去输出,这样客户端(浏览器)就能正常渲染、显示网页内容;
上图,一图胜千言:
代码实现
其实看明白上边的处理流程,剩下的便是用Java提供的API去实现了,比较简单,贴一段主要代码,完整代码后边有链接:
/** * 接收客户端的Socket,解析输入字节流,并返回结果. * @throws Exception */ private void process() throws Exception { // 2. 监听到有客户端(比如浏览器)要请求http://localhost:8080/,那么建议连接,TCP三次握手; Socket socket = ss.accept(); InputStream is = socket.getInputStream(); OutputStream os = socket.getOutputStream(); BufferedReader reader = new BufferedReader(new InputStreamReader(is)); /** * 3. 建立连接后,读取此次连接客户端传来的内容(其实就是解析网络字节流并按HTTP协议去解析); * GET /dir1/dir2/file.html HTTP/1.1 */ String requestLine = reader.readLine(); Logs.SERVER.info("requestLine is : {}", requestLine); if (requestLine == null || requestLine.length() < 1) { Logs.SERVER.error("could not read request"); return; } String[] tokens = requestLine.split(" "); String method = tokens[0]; String fileName = tokens[1]; File requestedFile = docRoot; String[] paths = fileName.split("/"); for (String path : paths) { requestedFile = new File(requestedFile, path); } if (requestedFile.exists() && requestedFile.isDirectory()) { requestedFile = new File(requestedFile, "index.html"); } BufferedOutputStream bos = new BufferedOutputStream(os); // 4. 解析到请求路径(比如此处是根路径),那么去根路径下找资源(比如此处是index.html文件); if (requestedFile.exists()) { Logs.SERVER.info("return 200 ok"); long length = requestedFile.length(); BufferedInputStream bis = new BufferedInputStream(new FileInputStream(requestedFile)); String contentType = URLConnection.guessContentTypeFromStream(bis); byte[] headerBytes = createHeaderBytes("HTTP/1.1 200 OK", length, contentType); bos.write(headerBytes); // 5. 找到资源后,再通过网络流将内容输出,当然,还是按照HTTP协议去输出,这样客户端(浏览器)就能正常渲染、显示网页内容; byte[] buf = new byte[2000]; int blockLen; while ((blockLen = bis.read(buf)) != -1) { bos.write(buf, 0, blockLen); } bis.close(); } else { Logs.SERVER.info("return 404 not found"); byte[] headerBytes = createHeaderBytes("HTTP/1.0 404 Not Found", -1, null); bos.write(headerBytes); } bos.flush(); socket.close(); } /** * 生成HTTP Response头. * * @param content * @param length * @param contentType * @return */ private byte[] createHeaderBytes(String content, long length, String contentType) throws Exception { ByteArrayOutputStream baos = new ByteArrayOutputStream(); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(baos)); bw.write(content + "\r\n"); if (length > 0) { bw.write("Content-Length: " + length + "\r\n"); } if (contentType != null) { bw.write("Content-Type: " + contentType + "\r\n"); } bw.write("\r\n"); bw.flush(); byte[] data = baos.toByteArray(); bw.close(); return data; }完整代码实现:BootstrapV1.java
问题
实现了一版WebServer,但是有什么问题呢?
- 我们让main线程去监听8080端口,并且main线程去查询资源、返回结果;
- 因为只main一个线程处理所有逻辑,就导致了我们首页的5个请求(一个index.html界面和4个图片资源)是串行的处理,即先处理了index.html文件,然后依次处理每个图片,如果同时有多个人打开浏览器请求,那么所有的请求也都是串行的;
感想
这一版仅实现功能,算是第一次迭代,有了一个可用的版本;接下来,我们会进行多次迭代,一步步的完善;其实实际业务开发中,不也是这样么,没有一开始就设计完美无缺的系统、都是多次迭代、运维出来的系统。
-
Java多线程系列

背景
温故知新、梳理自己的知识点;
业务开发过程中自己写多线程的场景其实并不是太多,但是又不能不了解多线程,我们整个编程环境就是在多线程下,一不小心,便会出现线程不安全的代码;
本系列文章重在讲解Java中如何应用多线程、先讲应用不讲原理,对:就是科普;
目录
以写一个Java版的WebServer的例子,去学习如何应用多线程编程中的一些知识点;
当然,这其中也会涉及到一些其它知识点,比如:Java Socket、重构、面向对象设计等;
本系列文章的正确打开方式:先将完整代码下载运行之、再亲手撸一遍、再查相关知识点、再后看每篇文章内容;
看完本系列:希望你知道如何构建一个简单的WebServer、学会应用多线程编程、知道业务上的增删改查是由哪些线程完成的;
为什么需要多线程
因为一个人的力量有限、群众的力量更大;
多线程编程面临的问题
- 线程互斥与同步
- 线程通信
理解这两个问题的关键点在于:共享变量;
实例学习多线程
先写一个简单WebServer
开始给主线程减压
开始给工作线程减压
缓解忙等问题
增加工作线程-线程池
JCU API实现
知识点
Java中多线程编程提供的解决方案
- JDK1.5前的实现,即:synchronized、wait、notify等机制;
- JCU的实现,即:lock、condition等机制;;
工作中的一些案例
业务开发过程中,也遇到过一些案例,比如死锁、线程不安全的代码,不过得慢慢找找。
总结
我不是一个聪明的人,至少我刚学编程的时候,对多线程编程这块理解的很慢,抓不住问题的核心点,以至于做了一些无用功,当时特别希望有个师傅、学长之类的人能指导一下、如果能手把手教就更好了;
写的这个小Demo希望可以给初学者一些帮助,当然也顺便梳理下自己的知识点;
如果后续有时间,会将这一系列录制成一个视频…;
如果再有时间,会再写其它系列文章:比如讲些线程底层原理、JVM实战等等;
引用
-
需要写单元测试吗

背景
工作中,不止一个同学提出过这样的问题:我们项目要写单元测试吗?
这个问题很宽泛,因为单元测试也只是我们解决问题的一种手段、工具,本身没有好坏、要不要写,抛开具体场景谈工具,都是耍流氓;
那么我来谈一谈,就针对我所做的工作,是否需要单元测试;
单元测试
是什么
单元测试,如果我们写了一个类的方法,那么我们就需要针对这个方法去写一些测试cases,以保证我们提供的方法正确性;
那么时间问题来了,如果我写的是POJO,那么其中的setter、getter方法要写单元测试吗?本来这些方法逻辑就极其简单、通过工具都是自动生成的,有些框架如lombok的使用直接能让我们免写手动写setter、getter;
即使有些逻辑复杂的方法,我们写的单元测试,但是也不一定能保证最终功能测试、集成测试、压力测试的时候管用啊;
带着这些问题,我们继续往下看。
能做什么
既然是测试,当然是为了保证质量,比如我写了一个方法,可能存在十种调用场景,我写了两种场景的调用cases,那么就能保证这两种场景的调用逻辑;
这么说我们都应该去写单元测试了吗?
我们最终是要保证开发的功能是正确的,但是只写单元测试其实是不能保证我们的功能最终正确性,那么我们直接针对提供的服务、功能写测试是不是就可以了,比如我提供了一个生成订单服务,我对这个生成订单服务做测试,是不是更好?
个人观点
个人经验来看,做业务后台开发,写功能测试的收益要比写单元测试的收益更高,这里的收益主要是指的投入时间与产出,重点关注对外提供的功能是否运行正确,功能测试时也会走到单个方法的执行处,虽然不一定所有方法都能覆盖到(这个主要看测试用例全不全);
目前我们做的不少业务都是有时间限制的,其实也就是成本控制,所以如何在有限资源(时间、人力等)下保证业务的快速上线、试错,才是王道,天下武功、唯快不破;如果说写单测能达到目的最大化、那么果断写单测,如果写功能测试能达到目的最大化、那么果断写功能测试;
一切选择都是权衡,付出了什么便会得到另外一些,看到一些新人经常会问写不写单测,其实他们从来就没写过单测,那么我的建议是,先抽空认认真真写几个单测,再来谈要不要的问题;可能是前些年TDD、XP被一些人鼓吹起来,大家不管新手老手都听到了单元测试这个词,好像没听说过走在路上都不好意思跟别人打招呼一样,技术都是工具,在适合的场景下去选择便好,没有万能的工具、没有银弹。
-
Java后台新人技术栈

为什么写这篇文章
今天有位校招同学问我,有没有什么技术资料可供学习,便于提前熟悉下公司用的技术;其实若简单敷衍下,我便一句话回复了:网上资料已经很丰富了、自己查有关Java的知识,话虽如此,但是如果这么回答基本上也跟没回答一样,想起自己当年毕业踩过的坑,如果能有一人在迷茫的时候指导一下、可能会少走一些弯路、成长会快一些,因此我想写下这篇新人需要了解学习的技术栈;
当然,我也只是根据目前自己的经历来总结的,或许若干年后自己再来看这篇文章,不一定都对,仅代表个人意见;
这篇文章面向哪些人
自己工作这几年,也带过几个新人,仅以自己这点经历写写,主要针对刚毕业、或毕业一两年还未入门的新人;
新人有什么特点
大部分新人都是一张白纸、可塑性强、有激情、时间充足、求知欲强等等,如果引导合适,潜力无穷,能很快成长为团队主力,虽然我当时没遇到这样的机会、但是我会尽力帮助我带的新人上手;
如何培养新人
我见过的培养新人方式有几种:
- 放养式:给新人的任务,完全靠新人自己、导师只看结果,新人如果有问题也会去指导,新人不主动问也不去找新人去沟通;
- 引导式:给新人的任务,先让新人自己去查资料、出方案,然后再给出导师自己的建议,定期给新人以大方向的指导:比如哪块知识薄弱需要加强;
- 分配式:给新人的任务,怎么做、如何实现都一一告诉新人,新人就像一个翻译机;
每个人性格不一样,培养策略也不一样,以上列的三种方式,不能说哪种好、哪种坏,因为不管哪种方式我都见过有不错的新人脱颖而出,也见过有表现平平的,成长主要靠自己,不过培养手段、环境是有助力作用的;
如果环境允许,我个人更倾向于引导式,因为这样可以让新人自己先去思考,也不致于工作跑偏,算是一种中庸策略吧。在此过程中我会让新人尽多的去试错,因为成长最快的方法就是让新人自己动手、自己试错、自己修复、自己总结,说百遍不如自己动手干一遍,比如今年入职的两个新人,做了一个需求,工期算是比较长、需求不算紧急,让两个人自己先去熟悉需求、出方案、做设计、写上线计划、主导上线、维护升级,当然这个过程中老人肯定是要给指导的,从两个新人刚入职到现在,基本上每人都可以搞定一中小系统;当然如果环境不允许,三种培养方式可能会混合着用,因为目标是保证业务的正常、顺利进行。
技术栈
目前做后台开发,主要用的编程语言是Java,所以仅针对后台开发-Java新人做一些建议;
以下我们公司所用到的一些基本知识点,随着时间,这些知识点可能会过时;
日志
建议日志组件:log4j2
基本上新人做需求,不会考虑打日志,后期线上维护查问题、没有日志即使来一架构师也定位不到问题,所以请新人先学会日志:打日志、查日志;
打日志:什么时候该打日志、打什么内容、日志格式如何;
查日志:登录线上机器,grep less cat tail等各种常用命令;
常用Linux命令
- grep/egrep/zgrep系列
- awk/sed
- top/netstat/ps/vmstat
当然还有很多命令,先会用基本的;
Java基础
Java语法、多线程、集合基本的API肯定是要会的; JVM的知识要有些了解;
框架
Spring SpringMVC
ORMapping
Mybatis
DB
MySQL; 索引原理要了解; 基本增删改查要会;
Web容器
jetty tomcat 可以了解下Spring Boot;
缓存
Redis
版本控制
Git
编译打包
Maven
RPC
Thrift 其它的如gRPC、Dubbo都可以了解; 可以再了解下Spring Cloud;
定时任务
Quartz
消息
Kafka
数据
实时数据处理:Storm、Spark、Flink; 列式存储:HBase; 可以了解下Hadoop系列;
开发工具
Idea
最后
当然,以上列出的是不全的,更多的还得工作中学习。
另,个人建议如果能早实习就早实习。
读万卷书、行万里路。
-
线上压测时要关注的指标

需要关注哪些指标
机器
数据库
缓存
网络
思考
机器指标有哪些
CPU
内存
磁盘
网卡
计算机组成原理
冯.诺伊曼
技术设计
技术设计应该考虑哪些因素?资源(人力、时间)、需求量;总结:在有限的资源情况下做出一些事情;
面向什么编程?QPS、功能、时间;
同样的代码如果QPS是50的时候一点问题没有,如果QPS是2000的时候,现有的技术设计已经不能满足需求了,所以我们在做技术设计的时候应该考虑什么?
首先要明确:业务场景(性能优化一定要结合业务场景)、业务调用量(如读写QPS)、数据量(要存储的数据量有多少)、扩展性(比如系统出现瓶颈时通过加机器就可横向扩展)、可维护性(毕竟软件是需要人来开发和维护的)
当然也要首先知道每种产品(缓存、数据库、机器、网卡等)的适应场景和承载能力,灵活根据业务需求去决定使用什么、不使用什么、什么时候引入;
当然也要了解人,毕竟是团队协作,团队每个成员当前状况、预期成长等等;
-
Java中生成字节码
为什么需要生成字节码
在什么场景下需要
有什么好处
生成字节码的方式有哪些
各有什么优劣,各有什么适用场景
运行时生成
编译时生成
-
论婆媳关系
-
为什么人和人是不同的
