柒八块表的博客
-
Spring Aop Deadlock Case

问题
隔壁组线上环境有一次发布,6台机器,5台发布成功,1台出现死锁,jstack打印出线程栈,当然为解决线上问题,我们立马对此应用进行重启、再次重启就没有死锁现象了;
用的Spring版本为3.1.2.RELEASE;
疑问1
为何同样的部署环境、同样的业务代码,6台机器,只有1台会出现死锁?
疑问2
为何出现死锁的机器,重启之后又没有死锁了么?
原因
通过jstack的线程栈分析,是两个线程,每个线程都要去争两把锁,分别叫锁1和锁2,线程1获得了锁1、等待获取锁2,线程2获得了锁2、等待获取锁1,互相等待对方释放资源,于是很经典的死锁发生的;
当然,此处我分析完jstack后进行了一些简化,实际的jstack更复杂,因为代码层层嵌套,获取的锁不止两个、且栈中存在公司代码不便贴出,故我将复杂例子简单化描述了;随后我会写一个Demo模拟这种死锁情况;
再贴一个官方Bug链接:SPR-14241
重现问题
在分析了死锁原因后,我写了一个Demo,可以通过IDE Debug去重现这个死锁问题:AopDeadlockTester.java
解决
其实查到问题原因后,想解决方法就容易的多了,当然、最官方还是得看上边贴的链接:SPR-14241
问题
Spring Aop 过程是怎样的
Spring 创建Bean的过程是怎样的
生成代理的方式有哪些
-
三读明朝那些事

两个人
写进历史的人很多,令我印象最深刻的有两个,王守仁、孙承宗;
了解一个人,多看看这个人的经历、做过的事、说过的话;
王守仁
真遗憾跟王守仁没生在一个时代,否则真想把心中各种问题都向他请教一遍,对于孔孟、程朱这些人倒不觉得他们厉害,因为这些人常常在实践中是失败者,而王守仁在理论和实践中都很出色,这就值得一学了。
了解心学后,是不是感觉真的会很爽,是不是真的会很快乐?
先去多实践、多读书,真不知道自己有没有可能也来个龙场悟道;
孙承宗
“夫攻不足守有余”。
至高无上的评价,明朝后期能从大局上力挽狂澜的也就孙承宗了,每当读到孙承宗这里,都感到莫大的遗憾;
每个朝代的后期都会存在遗憾,可能这就是历史、这就是现实;
人生百态
二百多年,那么多人物,你方唱罢我登台,人生各不同,有的少年得志如杨廷和、有的壮怀激烈如杨继盛、有的前程尽毁如伯虎兄、有的天助自助如张居正,每个人都是独一无二的、每个人都有自己的一条路要走,不管跌宕起伏也好、一帆风顺也罢,时也、命也;
历史,很有意思
历史,其实很有意思,都说以史为鉴,如果真的能以史为鉴,那么于谦就不会冤死、魏忠贤就不会上位,所以以史为鉴是不可能的,并且新的场景跟历史也不同一模一样,读史无非就是让自己的内心安静下来;
知行合一
心学要义,什么是知行合一,还得不断经过历练才能体会;
百姓
历史的车轮不断前进,总是苦了百姓,兴、百姓苦,亡、百姓苦;
天下
熙熙嚷嚷、利来利往;
-
Thrift Mock Server - 2

问题
继上一篇Thrift Mock Server,有同学问了,Thrift也支持注解方式开发,不用每次都得写IDL文件,生成Thrift的一堆类文件,我实际项目中用的注解,如何开发Mock Server?
IDL方式
我们先看下用IDL开发的流程,如图:

- 编写IDL文件;
- 将IDL文件编译成目标代码;
- 实现IDL文件中定义的服务方法;
- 发布Thrift服务;
- 服务提供方将目标代码打包供客户端引入、调用;
Thrift为了简化Java开发,支持纯Java的实现,用几个简单的注解便可将上述1~2两步给省掉;
当然了,有得有失、恒古不变,省掉的两步不是白省的,得靠其它地方做很多工作来弥补;
思路
注解方式调用流程
先分析问题,分析清楚了,便知道如何处理;
我们先来了解下Thrift注解调用的流程,如图:

其实这张图跟Thrift Mock Server的图类似,只是在目标代码这块不一样,即图中黄色两块:Codec-Client、Codec-Server,相比原来IDL的方式,我们其实还是需要目标代码,只是说目标代码不再由我们自己去生成,而是通过Facebook swift动态生成:
- 读取注解标注的服务;
- 用Codec编/解码动态生成Class文件;
- JVM载入这些动态生成的Class文件;
- 剩余的步骤跟IDL方式一样;
看到这个过程,其实如何Mock注解方式,我们便知道了,原来IDL方式的Mock方式,注解完全可以使用;
唯一不同的便是我们得根据注解方式去实现一遍,主要工作量在看懂swift api、生成每个服务的Codec;
我也实现了一个注解的demo:
先运行ThriftServerV2Demo.java,再运行ThriftClientV2Demo.java,便可看到结果;
此处只是拿原生的Thrift写了一个实现,离实际正式环境使用还有一定差距,不过思路是一致的,比如我们公司对原生Thrift做了一层封装,加入了服务自动注册、调用链追踪等功能,即支持IDL方式、也支持注解方式,我便按上边的思路实现了一个Mock Server。
总结
用注解方式我们提高了开发效率,但是引了新的问题,大家可以思考下,用注解方式又有哪些不如IDL的方面呢?
-
Thrift Mock Server
问题
当我们在写自动化case的时候,往往需要将外部的依赖mock掉,在我们公司,RPC组件用的Thrift,那么就涉及到一个问题,如何将Thrift给mock掉,并且我们这里是在做自动化测试(功能测试),不是单元测试,在单元测试的时候我们很容易mock。
自动化测试流程如下:

- 准备要Mock的数据传给Mock Server缓存起来;
- 测试对外提供的服务接口(比如订单系统提供给C端用户的下单接口);
- 订单服务会调用外部依赖(此处是Mock Server的Thrift依赖,如查询产品接口、支付接口);
- Mock Server会将第1步Mock的数据返回给业务系统;
由此我们便达到测试自己系统的功能而不受外部依赖环境的影响,不用再关心外部接口是否可以、返回数据是否一致,因为我们将所有的外部依赖都Mock掉。
难点
Thrift自定义了一套协议,根据IDL生成的Thrift类在服务调用端、服务提供端都需要,并且Thrift协议是按生成的类来封装字节,一个端口对应一个服务,如何在仅提供一个端口的情况下Mock多个服务?
思路
Thrift调用流程
我们先来了解下Thrift调用的流程,如图:
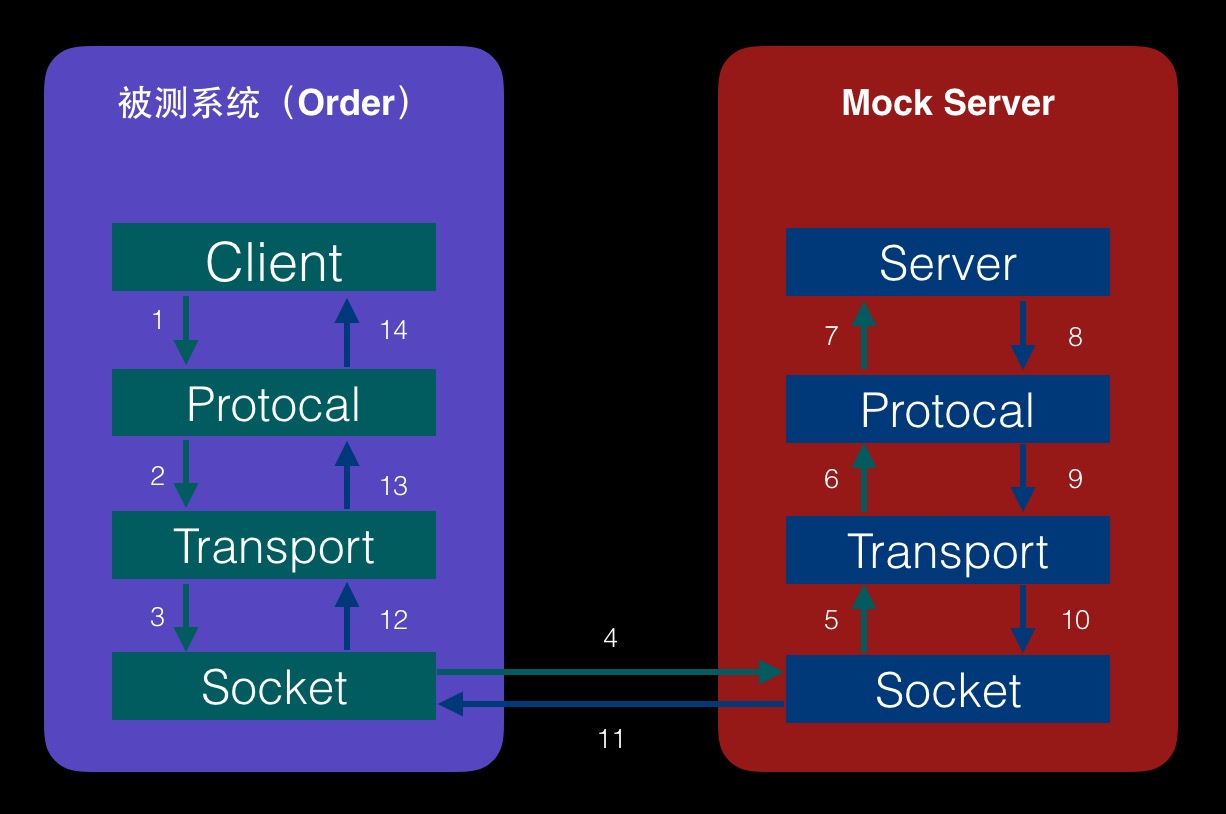
从图中可以看到,我们在很多点都可以做一些动作,达到我们Mock的效果;凡是图上标记数字(1~14)的调用处都可以;
整体上可以分为两类:Client端、Server端。
Client
在Thrift Client端做一层代理,将Client的请求都打到一个Mock Server端口上,在代理层中解析Mock的数据;如图:
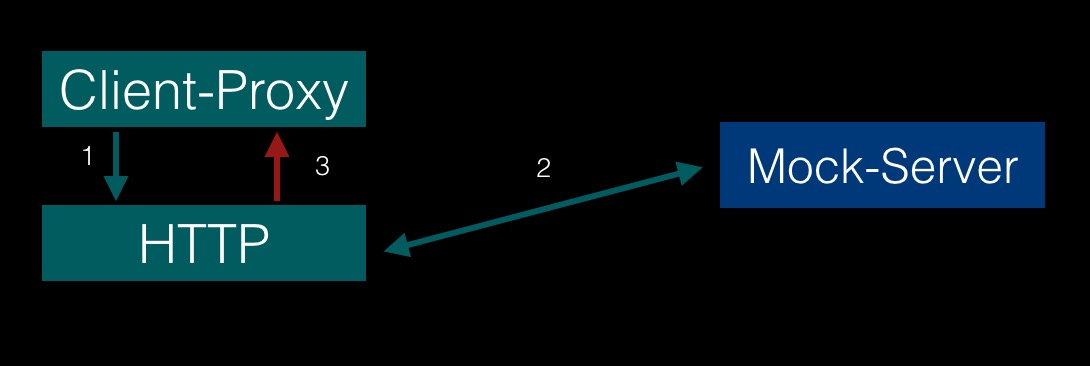
- 优点:容易实现;
- 缺点:业务系统要引入Thrift Client的代理,有侵入;
- 总结:重Client、轻Server;
Server
在Thrift Server端缓存Mock的数据,伪造成Thrift协议返回;
- 优点:业务系统无侵入;
- 缺点:实现难度要大一些;
- 总结:轻Client、重Server;
实现
理论上以上两种思路都可行,但是作为一个业务系统开发人员来说,我个人更倾向于Server端这种,因为这种方式对业务系统无侵入,更接入于真实的测试环境,尽管这种方式我们要比Client多做一些工作;
Client
对Thrift生成的Iface做一层代理, 业务方如下使用:
// 生成Iface的Proxy. HelloWorldService proxyService = HelloWorldServiceProxy(); // 调用say方法. Result ret = proxyService.say();HelloWorldServiceProxy的say方法如下实现:
// 代理类的实现 public Result say() throws TException { // 获取Mock数据,比如通过http接口获取Mock Server的Mock数据. mockData = httpClient.getMockData(); // 将Mock数据解析为Result对象 Result ret = paseMockDataToResult(); // 返回结果 return ret; }当然了,这里只是简单介绍一种思路,具体实现上见仁见智。
Server
说下Server端的实现,Thrift其实底层也还是对Java Socket的包装,只是在原生的Socket上面做了一些约定(即Thrift Protocal):比如前几个字节是TMessage头,后几个字节是TMessage尾等等,如果想清楚这点,那么我们实现起来就简单了。
按照我们上图Thrift调用流程中,从8到11这4步我们都可以做些动作,此处我选择在步骤10处返回Mock数据、直接操作Socket的InputSream和OutputStream,这样我可以不关心Thrift协议层的一些细节而达到目的;
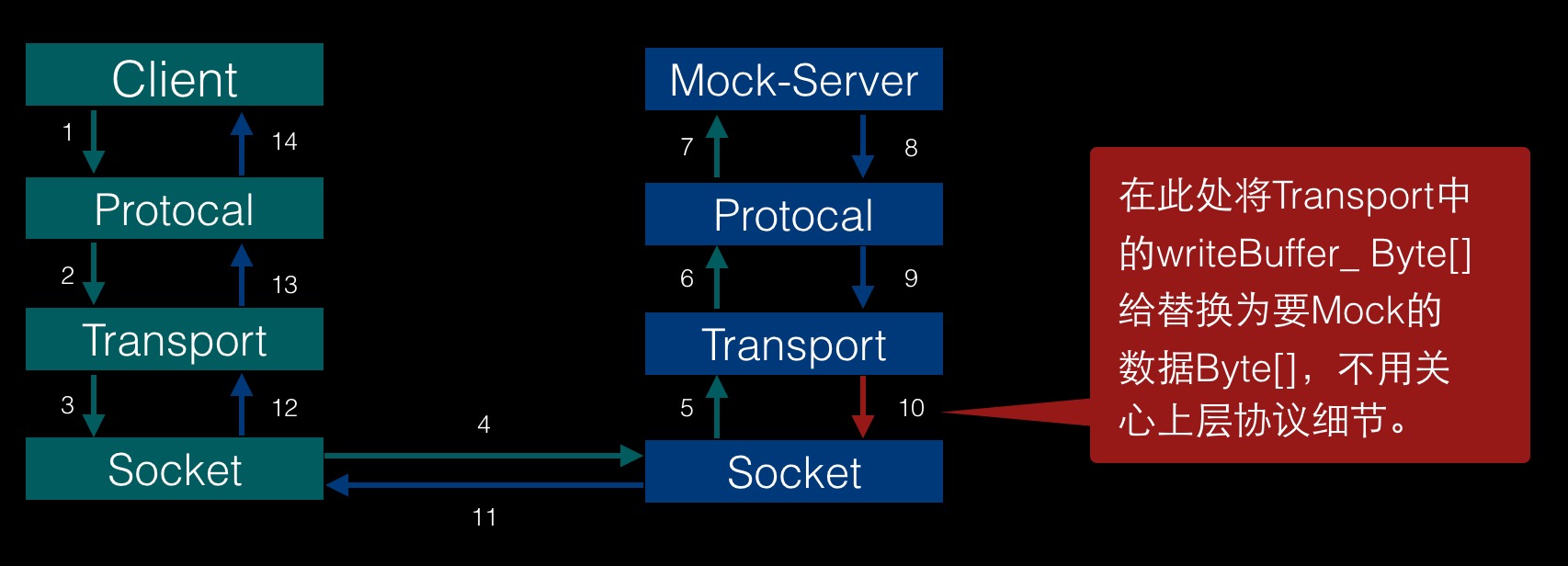
贴一段主要的代码逻辑:
private void mockDaynamicGetStrResult(TProtocol oprot, TMessage msg) throws TException { try { // 1. Mock返回数据,实际情况下Mock数据可以由Test Case通过HTTP接口传过来,Mock Server缓存. TestThriftService.getStr_result getStr_result = new TestThriftService.getStr_result(); ResultStr resultStr = new ResultStr(); resultStr.setValue("mockDaynamicGetStrResult......"); getStr_result.setSuccess(resultStr); TFramedTransport tFramedTransport = (TFramedTransport) new TFramedTransport.Factory().getTransport(null); TBinaryProtocol tBinaryProtocol = (TBinaryProtocol) new TBinaryProtocol.Factory().getProtocol(tFramedTransport); tBinaryProtocol.writeMessageBegin(new TMessage(msg.name, TMessageType.REPLY, msg.seqid)); getStr_result.write(tBinaryProtocol); // 2. 获取到Transport中的 writeBuffer_ Field writeBuffer = ReflectionUtils.findField(TFramedTransport.class, "writeBuffer_"); logger.info("writeBuffer : {}, accessable : {}", writeBuffer, writeBuffer.isAccessible()); ReflectionUtils.makeAccessible(writeBuffer); logger.info("accessable : {}", writeBuffer.isAccessible()); TByteArrayOutputStream fakeOutputStream = (TByteArrayOutputStream) writeBuffer.get(tFramedTransport); byte[] bytes = fakeOutputStream.get(); // 3. 偷梁换柱,将Mock Byte[] set到OutputStream中. TByteArrayOutputStream outputStream = (TByteArrayOutputStream) writeBuffer.get(oprot.getTransport()); logger.info("outputStream : {}", outputStream); outputStream.reset(); outputStream.write(bytes); } catch (Exception e) { logger.error("mockDaynamicGetStrResult error", e); } }此处我实现了一个Server端的demo:
先运行ThriftServerDemo.java,再运行ThriftClientDemo.java,便可看到结果;
此处只是拿原生的Thrift写了一个实现,离实际正式环境使用还有一定差距,不过思路是一致的,比如我们公司对原生Thrift做了一层封装,加入了服务自动注册、调用链追踪等功能,我便按上边的思路实现了一个Mock Server。
其它
对于其它一些Mock Server实现方式,我见过的有:
- 上传Thrift IDL自动生成Thrift类、配置端口再通过Shell等脚本启动一个Mock服务;
- 将业务系统依赖的所有外部Thrift接口Jar都引入进来,所有接口都实现一遍,这种方式Mock Server依赖的Jar会越来越多,每个服务都需要配置一个端口,对于一个小组还可行,但是对于整个公司级别的Mock Server便不可行了;
总结
以上为自己做业务系统时遇到的一个Mock问题及想法,不管哪种实现,没有一种标准答案,解决问题达到效果即可,心即是理。
-
问题-答案

年岁俞长,疑问俞多;
每到一定年岁,都会多懂一些道理,甚至是相似的道理扎堆被看到、听到,为何?
为什么这些道理别人都已经懂得,而我却不知道?
所有道理的背后是不是有着某种规律?是否可以一气知所有道理,而非到一阶段才知一阶段的道理?
-
设计模式-责任链之抛砖引玉

背景
最近遇到几处使用了责任链模式的地方,所以想总结一下。
讲个故事
上小学的时候,班里经常会有同学说,帮我给个纸条给那谁谁谁,比如坐第一排的白居易同学新写了一首诗,要传纸条给坐在第五排的刘禹锡同学炫耀一下,于是通过中间这一个个同学传递,便是一个典型的责任链模式;
另一个故事,在《who build america》纪录片中,石油大王Rockefeller为打破运输渠道被铁路大亨Vanderbilt垄断的局面,出资修建布满全国的石油管道,这一节节的石油管道,也是一个典型的责任链模式;
由此可见,责任链模式的思想在生活中处处可见;
是什么
责任链模式到底是什么?
- 不就是烤串么?
- 不就是水管么?
- 不就是链表么?
- …
对,上边的这些比喻都没问题,问题的关键是学以致用;往往当我们在实际的业务中,遇到类似场景却不知道如何应用了;
有什么用
不用责任链模式有啥问题呢?用if else、for each信手拈来、照样实现业务逻辑、照样上线运行代码、照样拿工资,没准比那些使用责任链模式的人拿的薪资还高;
不错,如果将上边这句话中的
责任链模式换成其它任意一种设计模式,都是说的通的,并且在一些使用函数式编辑语言的同学眼中、设计模式这东西根本就不应该存在,那我们还有必要用责任链模式么?在我看来,使用责任链模式有一些好处:提升代码扩展性、更容易做到单一职责;当然,前提是得用对场景;
举例
对于广大程序猿来说,说一万遍理论不如直接上实例,下面我们就以几个经典开源项目为例,介绍下责任链这个模式,用最后附上一个我在实际业务开发中用到的场景;
Unix
当我在自己home目录下执行
ls | grep c | sort -r这个命令组合,即先通过ls命令查找home目录下的所有文件及文件夹,再通过grep命令查找到包含字母c的文件、文件夹名,再通过sort命令根据文件、文件夹名倒序排列;> ls | grep c | sort -r workspace Public Pictures Music Documents CLionProjects Applications AndroidStudioProjects在这个命令组合中,符号
|起到了一个串连的作用,通过标准的接口将其中的每个命令(lsgrepsort)串连起来,而每个命令就是责任链中的一个节点,每个节点做好自己的一件事情,通过标准的接口将输出交给下一个节点直至结束;做一件事、把它做好;(这是不是就是单一职责原则)
Servlet
在Java Servlet规范中,有这么两个接口:
FilterChain和Filter,比如下面这个web.xml配置了两个Filter,<!-- HTTP请求编码处理的Filter --> <filter> <filter-name>encodingFilter</filter-name> <filter-class> org.springframework.web.filter.CharacterEncodingFilter </filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> <init-param> <param-name>forceEncoding</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>encodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <!-- HTTP跨域请求处理的Filter --> <filter> <filter-name>crosFilter</filter-name> <filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class> <init-param> <param-name>targetFilterLifecycle</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>crosFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>用图来描述一下上边的配置:
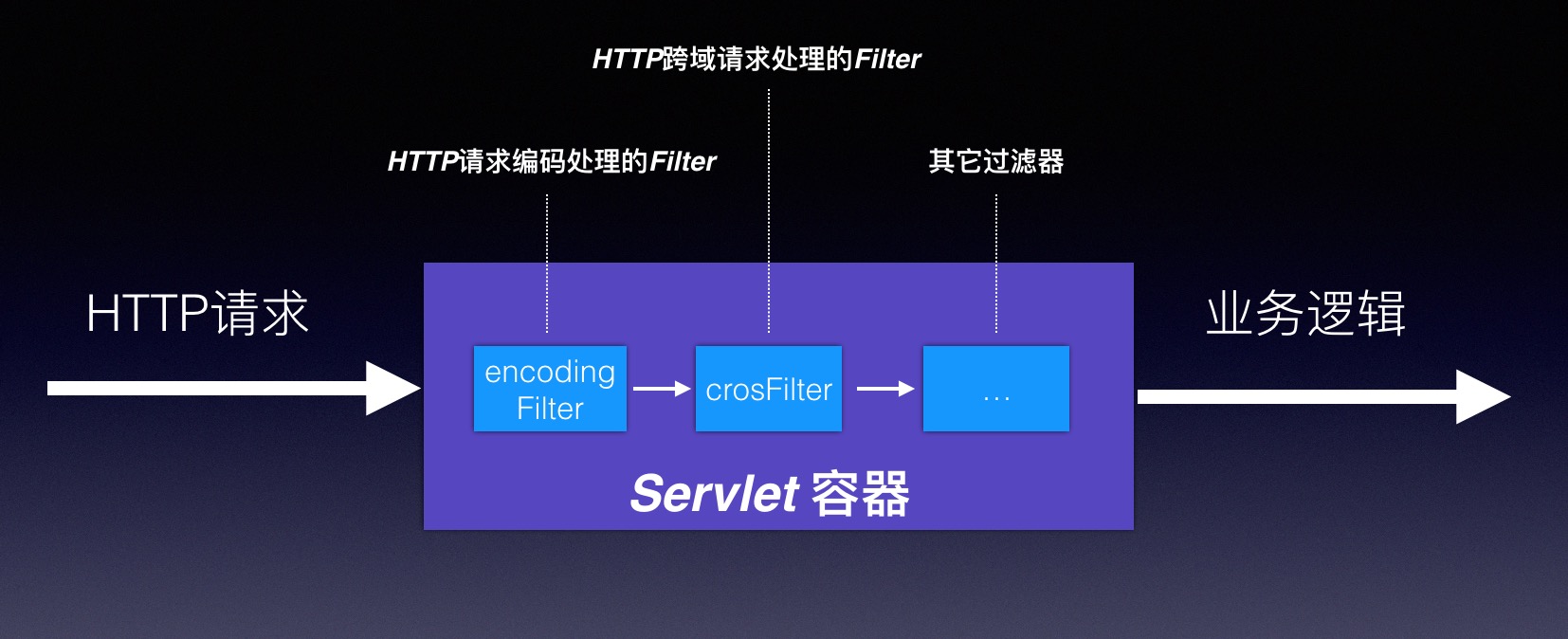
当HTTP请求到达时,Servlet容器(比如大家常见的Tomcat、Jetty等)都会将
web.xml中配置的节点(即filter)串连起来,一个个执行,其中每个节点执行完自己的任务将请求交由下一个节点执行;Servlet容器实现了
FilterChain,我们只需要实现自定义Filter,来看看这两个接口声明:// 要实现自己的逻辑。 public interface Filter { /** * 初始化方法 */ public void init(FilterConfig filterConfig) throws ServletException; /** * 执行具体的逻辑,并声明各节点统一的方法 */ public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException; /** * 销毁方法 */ public void destroy();// 容器去实现责任链,将每个节点串连起来 public interface FilterChain { /** * Causes the next filter in the chain to be invoked, or if the calling filter is the last filter * in the chain, causes the resource at the end of the chain to be invoked. * * @param request the request to pass along the chain. * @param response the response to pass along the chain. */ public void doFilter(ServletRequest request,ServletResponse response) throws IOException, ServletException; }Servlet规范给我们提供了一个比较标准的接口声明,为什么这个地方可以用责任链模式?来分析下使用场景:一次HTTP的执行过程,是一个典型的请求/应答模式,在执行过程中,不同的业务可能会有不同的逻辑,比如应用A需要有跨域的处理,应用B需要有黑白名单鉴权的处理,在整个HTTP执行流程中我们需要能灵活的配置不同的服务节点,用责任链很好的解决了面临的需求;
此处,
FilterChain就类似unix命令中的|符号的作用,而Filter就类似ls、grep这样的具体命令,每个Filter都一个统一的方法doFilter。Tomcat
Tomcat是Servlet规范的一个实现,被人称为Servlet容器,当然Tomcat也是一个Web容器,能处理Web请求,作为Web容器,Tomcat要将浏览器传过来的HTTP网络流进行解析处理。
场景是这样:当一个HTTP请求到达时,在Web处理这一层,Tomcat要做很多的工作,比如记录访问日志、请求加解密、SSL认证等工作,并且这些工作有些业务是需要、有些业务是不需要的,需要Web容器能灵活的配置,于是Tomcat再一次的使用了责任链模式。
Tomcat抽象出来了一个
Valve这个接口:声明责任链中的节点,抽象出来了一个Pipeline:将责任链中的所有节点串连起来,就像这两个单词的字面意思一样,Valve:水龙头、阀门,Pipeline:水管、管道,看图: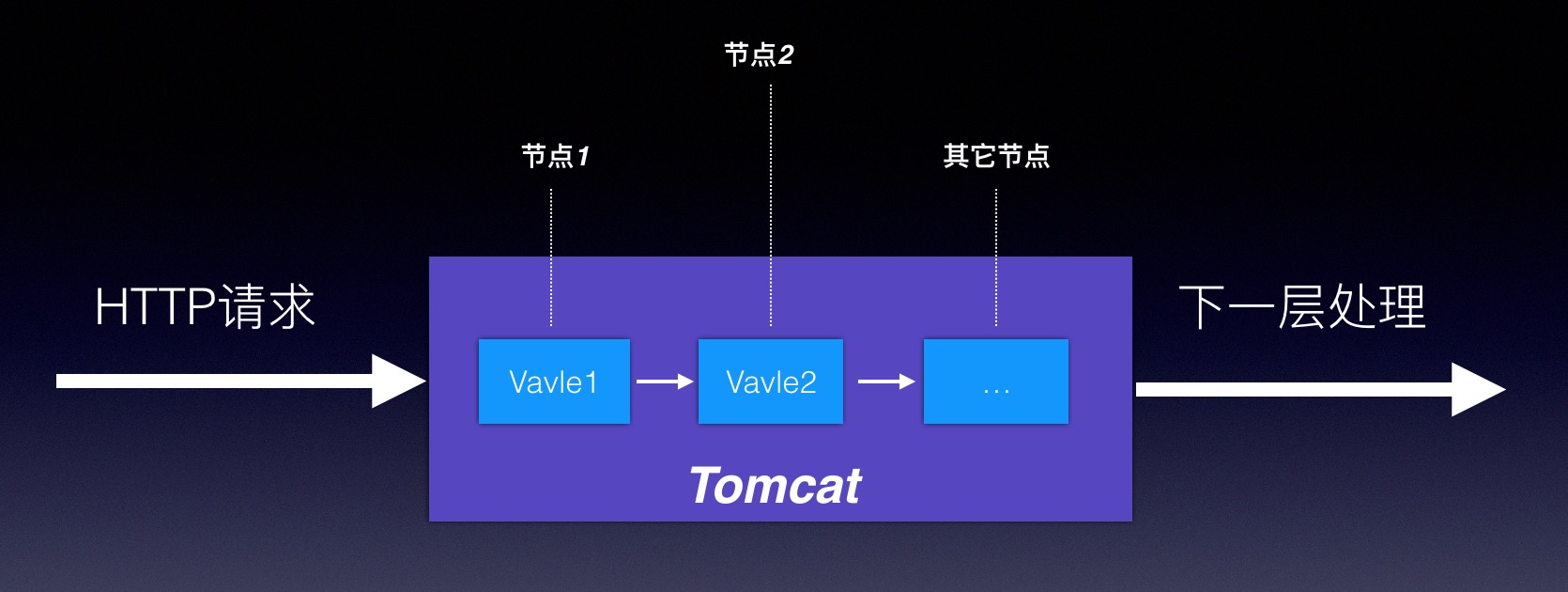
其实这张图和上边Servlet是一样,我们再来看下Tomcat是如何声明这两个接口的:
package org.apache.catalina; import java.io.IOException; import javax.servlet.ServletException; import org.apache.catalina.connector.Request; import org.apache.catalina.connector.Response; /** * 每一个Vavle都是责任链上的一个节点,承担具体的功能。 */ public interface Valve { public String getInfo(); public Valve getNext(); public void setNext(Valve valve); /** * 责任链中每个节点统一的接口 */ public void invoke(Request request, Response response) throws IOException, ServletException; public void event(Request request, Response response, CometEvent event) throws IOException, ServletException; }每个节点都要实现这个接口,具体的功能在
invoke方法中实现;Tomcat内部有几十个这种
Vavle的实现,其实Tomcat处理HTTP的核心流程都是用一连串Vavle实现的,如图:
再来看
Pipeline:package org.apache.catalina; /** * 管道,将责任链中的所有节点串连起来,决定了节点之间的调用顺序。 */ public interface Pipeline { public Valve getBasic(); public void setBasic(Valve valve); public void addValve(Valve valve); public Valve[] getValves(); public void removeValve(Valve valve); public Valve getFirst(); }这里Tomcat在管道中又加入了自己的一些操作,这里我们不做过多介绍,
Pipeline的核心作用是将节点串连起来,其实内部是通过类似单向链表来实现的,当然你也可以其它数据结构来实现;此案例中,
Pipeline就类似unix命令中的|符号的作用,而Valve就类似ls、grep这样的具体命令,每个Valve都有一个统一的调用方法invoke。Netty
Netty是Java领域的一个开源IO通信组件,不少开源项目都用Netty作底层通信,比如阿里的RPC框架Dubbo,Netty有一个IO事件处理流;
场景是这样的:每一次IO交互,都是一个IO读、写操作流(在Java中被称为
Channel),而Netty会将读、写封装成I/O事件进行处理,比如编码、解码、报文压缩等,Netty是如何应用责任链模式的呢?它抽象出ChannelPipeline、ChannelHandler这两个接口,ChannelHandler是责任链上处理具体逻辑的节点,ChannelPipeline将这些节点串连起来,看Netty自己的源码注释便一目了然:* <pre> * I/O Request * via {@link Channel} or * {@link ChannelHandlerContext} * | * +---------------------------------------------------+---------------+ * | ChannelPipeline | | * | \|/ | * | +---------------------+ +-----------+----------+ | * | | Inbound Handler N | | Outbound Handler 1 | | * | +----------+----------+ +-----------+----------+ | * | /|\ | | * | | \|/ | * | +----------+----------+ +-----------+----------+ | * | | Inbound Handler N-1 | | Outbound Handler 2 | | * | +----------+----------+ +-----------+----------+ | * | /|\ . | * | . . | * | ChannelHandlerContext.fireIN_EVT() ChannelHandlerContext.OUT_EVT()| * | [ method call] [method call] | * | . . | * | . \|/ | * | +----------+----------+ +-----------+----------+ | * | | Inbound Handler 2 | | Outbound Handler M-1 | | * | +----------+----------+ +-----------+----------+ | * | /|\ | | * | | \|/ | * | +----------+----------+ +-----------+----------+ | * | | Inbound Handler 1 | | Outbound Handler M | | * | +----------+----------+ +-----------+----------+ | * | /|\ | | * +---------------+-----------------------------------+---------------+ * | \|/ * +---------------+-----------------------------------+---------------+ * | | | | * | [ Socket.read() ] [ Socket.write() ] | * | | * | Netty Internal I/O Threads (Transport Implementation) | * +-------------------------------------------------------------------+ * </pre>其实Netty做了更丰富的抽象,比如抽象出
Inbound Handler、Outbound Handler,这里我们不做过多介绍;实际业务系统中应用
实现设计模式,比猫画虎我们都会,关键是用对场景、学习致用,这里我举一个在业务开发中用的地方,不一定合适、抛砖引玉、仅供参考;
场景:有一个业务量比较小的订单系统,日订单量几千到几万的样子,在下单的操作时,有如下业务逻辑:参数转换、参数校验、逻辑校验、风控、锁库存、创建订单、触发订单事件等操作,并且之后随着业务需求的变化还可能加入其它逻辑如幂等判断、限流、防抓取,整个过程如下图:

这里我抽象出
PipelineService、VavleService两个接口,其实从名字就可以看出,是从Tomcat那里学来的,VavleService是责任链中执行业务逻辑的节点,PipelineService将这些节点串连起来;来看这两个接口的声明:/** * 1. vavle 可以排序. * 2. 可以跳过其中某些vavle不执行. * 3. 可以在某个vavle上中断执行流程. * 4. 需要有一个返回结果,提供给上游使用. * 5. 不同场景可以定义不同的执行链. * 6. 前一个vavle的结果,可以给后边的vavle使用. * 7. 支持vavle的回滚操作. */ public interface VavleService { VavleResult execute(PipelineRequest request, PipelineResponse response) throws Exception; String getName(); } /** * 将责任链中每个节点串连起来。具体实现上就是一个ArrayList,并且加上了跳表的功能。 */ public interface PipelineService { void start(PipelineRequest request, PipelineResponse response); }在业务中下单的逻辑都是通过
VavleService的子类来实现的,如下:<!-- XX业务下单流 --> <bean id="userCreatePipelineService" class="com.service.pipeline.UserPipelineService" scope="prototype"> <property name="vavleList"> <list> <ref bean="orderBaseParamCheckVavleService"/> <!-- 校验订单基本参数 --> <ref bean="orderRepeatCheckVavleService"/> <!-- 校验重复下单 --> <ref bean="createParamConverterVavleService"/> <!-- 填充订单参数 --> <ref bean="orderParamCheckV2VavleService"/> <!-- 校验子下单参数 --> <ref bean="logicCheckVavleService"/> <!-- 订单金额校验 --> <ref bean="riskControlVavleService"/> <!-- 风控校验 --> <ref bean="generateOrderSnVavleService"/> <!-- 生成订单唯一编号 --> <ref bean="stockLockService"/> <!-- 锁库存 --> <ref bean="orderCreateVavleService"/> <!-- 生成订单 --> <ref bean="orderStatusChangeEventVavleService"/> <!-- 订单状态变更事件 --> <ref bean="createToPayAdapterVavleService"/> <!-- 下单到支付参数转换 --> <ref bean="payCheckVavleService"/> <!-- 支付参数校验 --> <ref bean="payApplyVavleService"/> <!-- 请求预支付 --> <ref bean="orderStatusChangeOldVavleService"/> <!-- 订单状态变更事件 --> </list> </property> </bean>如果之后在业务需求要再加其它逻辑,去写一个
VavleService的实现类即可,并且节点之间的顺序可灵活调整,在新的版本中我们还加入了支持某节点业务回滚的操作如:锁库存成功但是生成订单失败、此时要返还库存;此处下单场景使用责任链,不一定合适,但多了一种尝试,写
if else也是写,换种思路也是写,当然,前提是保障业务正常;总结
很多优秀的开源框架都会用到设计模式,正所谓:无模式不框架,学习设计模式,一个比较好的途径就是看别人如何使用。
但是设计模式真的有用么?相信一百人心中会有一百个答案,觉得有用就了解下、觉得没有也无所谓,依旧不影响日常工作,当
if else嵌套的实在难以忍受再来抽象一层也未尝不可。
-
Spring中几个关键接口
- aware
- BeanFactoryAware
- ApplicationContextAware
- BeanPostProcessor
- ImportBeanDefinitionRegistrar
- FactoryBean
- InitializingBean
aware
BeanFactoryAware
ApplicationContextAware
BeanPostProcessor
ImportBeanDefinitionRegistrar
FactoryBean
InitializingBean
-
读书思考
-
如何避免中年危机

最近看了条消息:如何评价 2017 年初华为开始「清理」34 岁以上的职员,又一次挑起了我对中年危机的思考,因为眼看我也快到30岁了,却还没什么核心竞争力,只不过是一枚普普通通的北漂。
中年危机的思考,其实在刚毕业那会就有,只是当时更紧迫的事情是找工作、迷途寻路,随着工作年限增长、危机感越来越重。
如何迈过去这道坎,还得问自己,如果自己离开公司这个平台,能做什么?有什么核心竞争力?还能不能在这个城市存活?
我是一名程序员,步入28岁,可以做些应用开发,像我这样的程序员13号线一抓一大把,很容易被其它人替代,并且我有家庭、即将有自己的孩子,工作时间、精力肯定比不上刚毕业的年青人,现在的年轻人技能栈越来越丰富,我则是不进而退,个人抗风险能力太低、家庭抗风险能力同样也低,目前我已在危机之中。
希望在30岁的时候,我能够不再为工作而担心,至少以自己的技能可以让工作来找我;
更或者,我能找到副业,保障家庭收;
心学要旨在:知行合一,为什么明白那么多人生道理、却依然过不好这一生,因为根本就是不知,知行本是一体,不行便是不知、行过才知;
持续学习,这才是保持自己永不落后的源泉,快速学习;
英语还是要坚持的;
编程技能扩展,不要给自己设限,不要成为一个易被替换的螺丝钉,多一些尝试;
最坏的时代、最好的时代;
规划好时间,且行且思、多总结;
-
2017书单